Test your AI agent using AI-based Test suites
Automated AI agent testing (Agentic testing) allows you to validate the functionality, performance, and accuracy of your AI agents built on the agentic platform without relying on manual testing.
With Automated testing, you can:
- Generate test cases from your Knowledge base
- Replay saved Copilot sessions
- Retest past user conversations
- Simulate end-to-end flows with scenario-based testing
It helps bot developers, QA engineers, conversation designers, and product owners who need to validate AI agent performance with every change or deployment across different environments.
Manual testing whether through preview windows or live sessions is time consuming. It requires creating test cases, checking each step, and revalidating after every change. Automated testing simplifies this by enabling you to create, run, and review test cases with ease, saving time and ensuring reliability.
Key capabilities of Agentic AI testing
- Test from multiple sources: Generates QnAs (Test cases) from Knowledge Base articles, Copilot sessions, past conversations, or custom scenarios.
- Smart response evaluation: Use configurable thresholds for accuracy and empathy to validate if responses are relevant and context-aware.
- Goal-based scenario simulation: Simulate realistic conversations using user rules and intents to test how the AI agent performs in complex, end-to-end flows.
- Cross-environment validation: Run tests across environments—like sandbox and production—to detect issues before they impact users.
- Automated regression checks: Revalidates existing test cases to ensure that updates to prompts, workflows, or configurations do not break previously functioning interactions.
Limitations
- Test cases can only be executed in lower-tier environments such as Sandbox or Development. Testing is not available in Production or Live environments.
- You can run up to 200 test cases in a single execution. Each test is evaluated based on configurable thresholds such as Accuracy and Empathy with optional support for custom evaluation rules.
Types of test cases
Automated AI agent testing supports four test case types, each designed to validate different aspects of an agent's performance to ensure consistent behavior across updates and environments.
-
Knowledge base test case: Knowledge Base (KB) test case helps you verify if the AI agent is responding accurately based on the documents uploaded in the Knowledge Base. It ensures the agent retrieves the correct information from those files when answering questions. This is especially useful when handling large volumes of content like PDFs, website links (URLs), or data from APIs.
In the KB test case section, you can view the list of documents uploaded to the Knowledge Base. For each document, a question and answer pair (FAQ) is generated. You can generate FAQs for up to 100 documents at a time. When you run the test, the AI agent is asked these questions to check whether it responds with the expected answers to validate that it understands and uses the document content correctly.
-
Copilot saved session: Copilot saved session test case allows you to capture and save user-agent interactions during a conversation within the AI Copilot. These saved sessions are useful for testing and debugging purposes. When a session is saved, it records the complete conversation between the user and the AI agent, including prompts, responses, and conversation context.
Once a session is saved in the Copilot Saved Session test case, it can be tested to evaluate how the AI agent performs based on that specific conversation.
-
Scenario-based testing: Scenario based testing simulates goal-driven user journeys, such as booking a ticket or raising a refund request. You can define user attributes like name, location, preferences, or intent to set up the context. The AI agent then uses this context to generate up to 10 scenarios per agent using this information.
If the auto-generated scenarios do not cover specific cases you want to test, you can create custom scenarios. You provide key details, and the AI fills in the remaining conversation flow, which you can edit further to match your exact requirements. These scenarios help test how well the agent handles changing inputs, context management, and different types of queries.
Testing works on a credit system with a daily limit of 2,000 credits. Credits can be used for Knowledge Base, Copilot sessions, and Scenario-based tests. Each Knowledge Base test case consumes 1 credit per test case, while each Copilot session and Scenario-based test case consumes 10 credits.
Test case settings
Automated testing provides two modes Evaluation and Simulation to help you measure how well your AI agent is performing.
-
Evaluation
Evaluation checks whether your AI agent is giving the right answers and responding in the right tone. Use this mode when you want to test if the AI agent is giving correct responses after making updates to your knowledge base, prompts, or workflows. You need to define two key metrics before running the tests:
- Accuracy: Measures how correct and relevant the agent’s response is to the user’s query. Suggested threshold: 75 for optimal accuracy.
- Empathy: Measures the tone of the response whether it is polite, helpful, or formal based on your brand guidelines. Suggested threshold: 75 for optimal empathy.
- Rules: You can also define what rules need to be followed by agent while running a test case, such as:
- Avoid casual language or jokes
- Use specific phrases or keywords
- Follow a defined tone (example, professional or friendly)
How it works:
- Set thresholds for both accuracy and empathy (example, 80% accuracy and 90% empathy).
- If a response falls below either threshold, the test case is marked as failed.
-
Simulation
Simulation mode is used when you want to test how the AI agent handles more complex, realistic conversations. It is especially useful for testing full user journeys like booking a flight, troubleshooting a product, or gathering customer information where the agent needs to maintain context across multiple steps.
In this mode, you test a user by setting up attributes such as Name, Location, Preferences, and Intent (what the user wants to do) by defining the rules. This helps test how well your agent performs in real-time scenarios where it needs to understand context and ask follow-up questions.
Reports
After configuring Evaluation and Simulation settings for automated AI agent testing, you can run test cases to generate detailed reports.
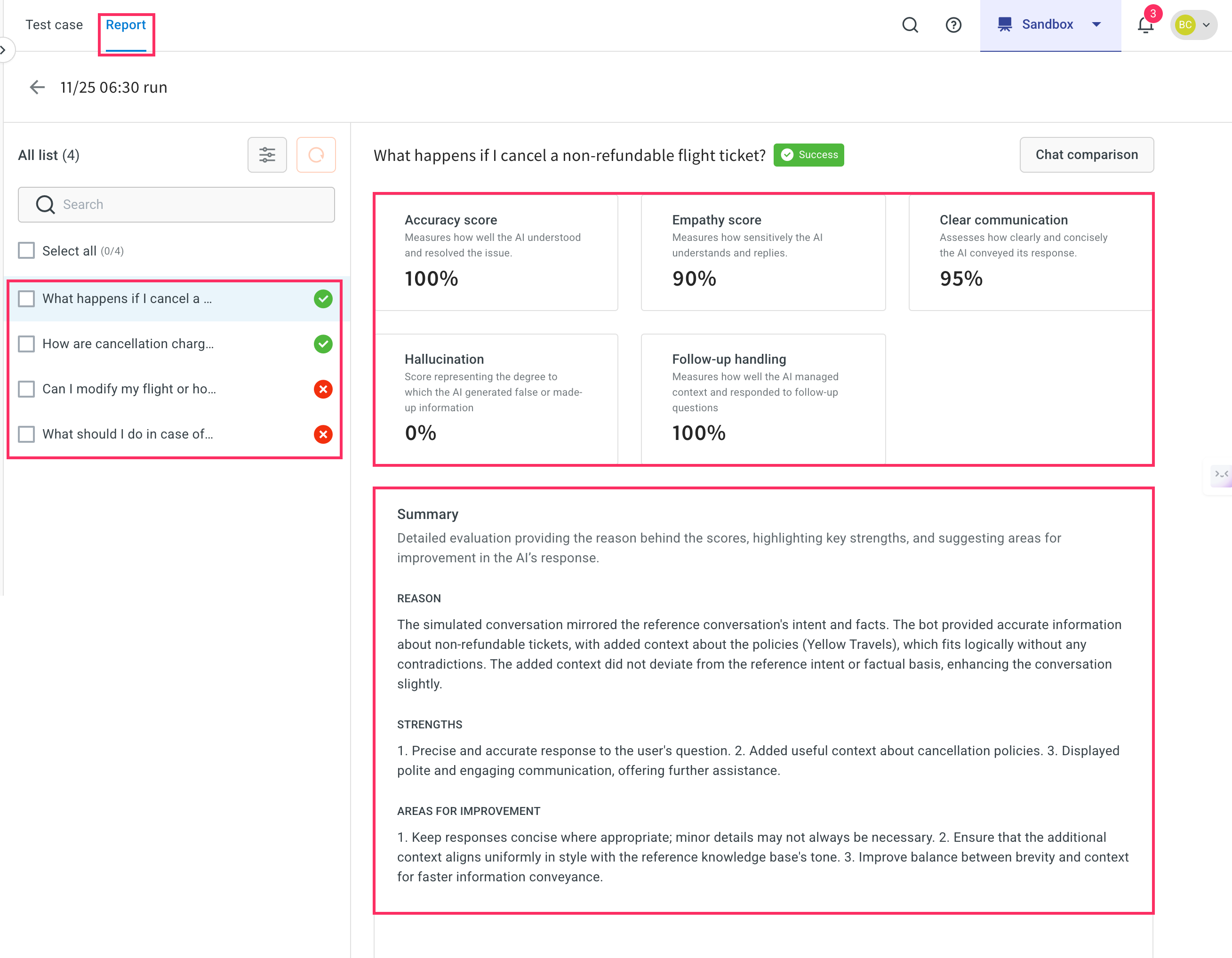
Each test case is marked as either Success (✔️) or Failure (❌) based on whether it meets the predefined thresholds for key performance metrics.
Performance metrics
- Accuracy score: Measures how well the agent understood the user's question and responded with a correct and relevant answer.
- High value (example, 100%): Agent fully understood and correctly resolved the query.
- Low value (< threshold): Indicates misinterpretation or incorrect/missing information.
- Empathy score: Evaluates whether the response uses an appropriate tone, empathetic, professional, or friendly depending on your use case.
- High value (example, 90%): The bot responded with a suitable tone.
- Low value: Response may sound robotic or indifferent.
- Clear communication: How clearly and concisely the agent conveyed its response.
- High value (example, 95%): Well-structured, easy-to-understand replies.
- Low value: Confusing, verbose, or poorly formatted answers.
- Hallucination: Indicates if the agent generated made-up or incorrect information not present in the knowledge base.
- 0% is ideal, showing no false content.
- Higher value (>0%): The agent introduced misleading or fabricated information.
- Follow-up handling: Evaluates how well the agent managed ongoing conversations and retained context.
- 100% indicates excellent context handling.
- Lower scores suggest poor continuity, requiring users to repeat themselves.
Summary
Provides a overview of the test case outcome and scores. It consist of three parts:
- Reason: Describes how the agent's response aligned with the user's intent and the expected answer. Example: The agent responded with accurate, policy-based information and maintained relevance to the query.
- Strengths: Highlights the positive aspects of the response. Examples include:
- Accurate answers
- Helpful added context
- Polite tone and further assistance offered
- Areas for improvement: Suggests where the response could be optimized. For example:
- Make responses more concise
- Avoid unnecessary repetition of policy details
- Balance added context with clarity
Execute test case
Knowledge base
To test knowledge base, follow these steps:
-
Navigate to Automation > Test suites.

-
Select Knowledge base > click + Add document.
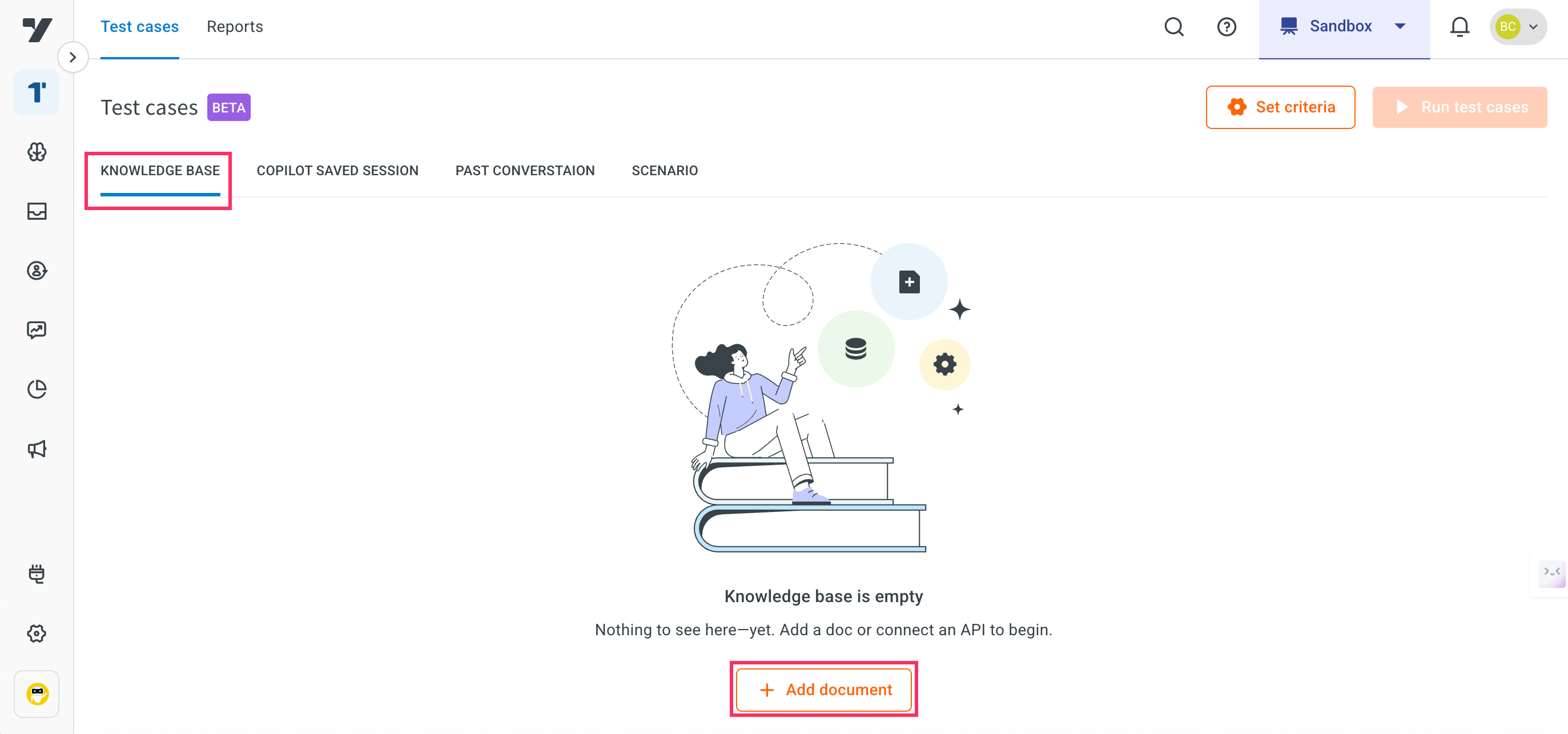
- This will navigate you to the Kownledge base module.
-
Click Add file.
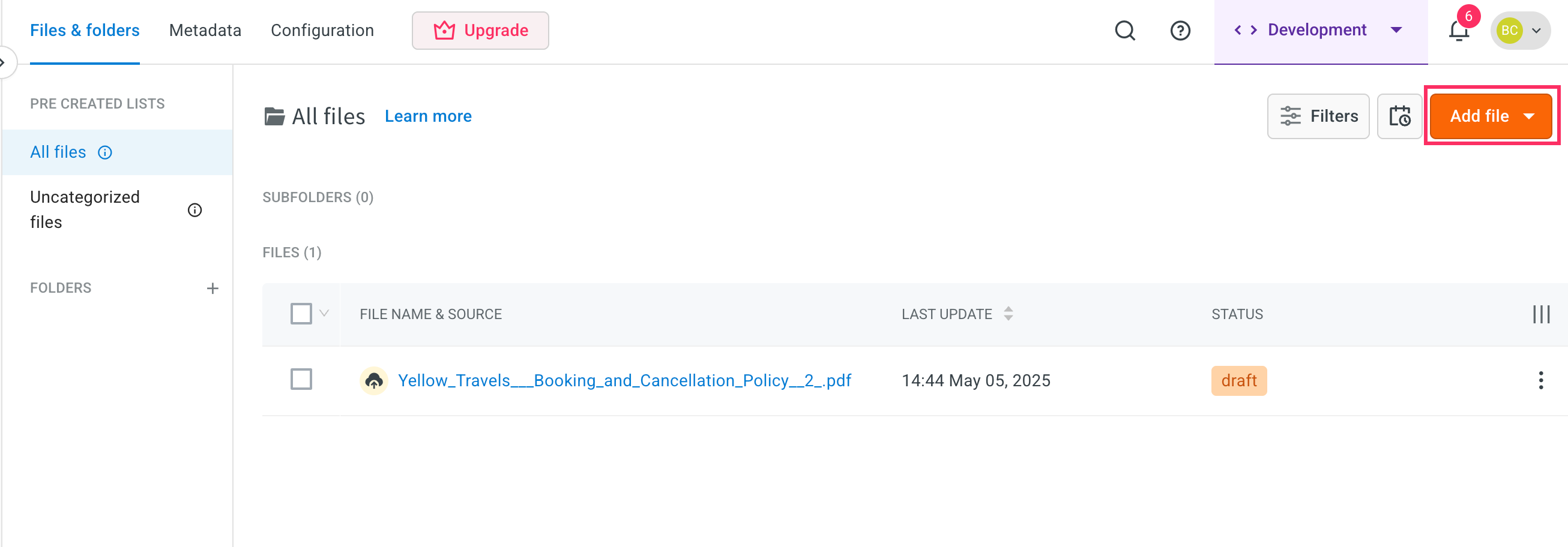
-
Click Upload files.
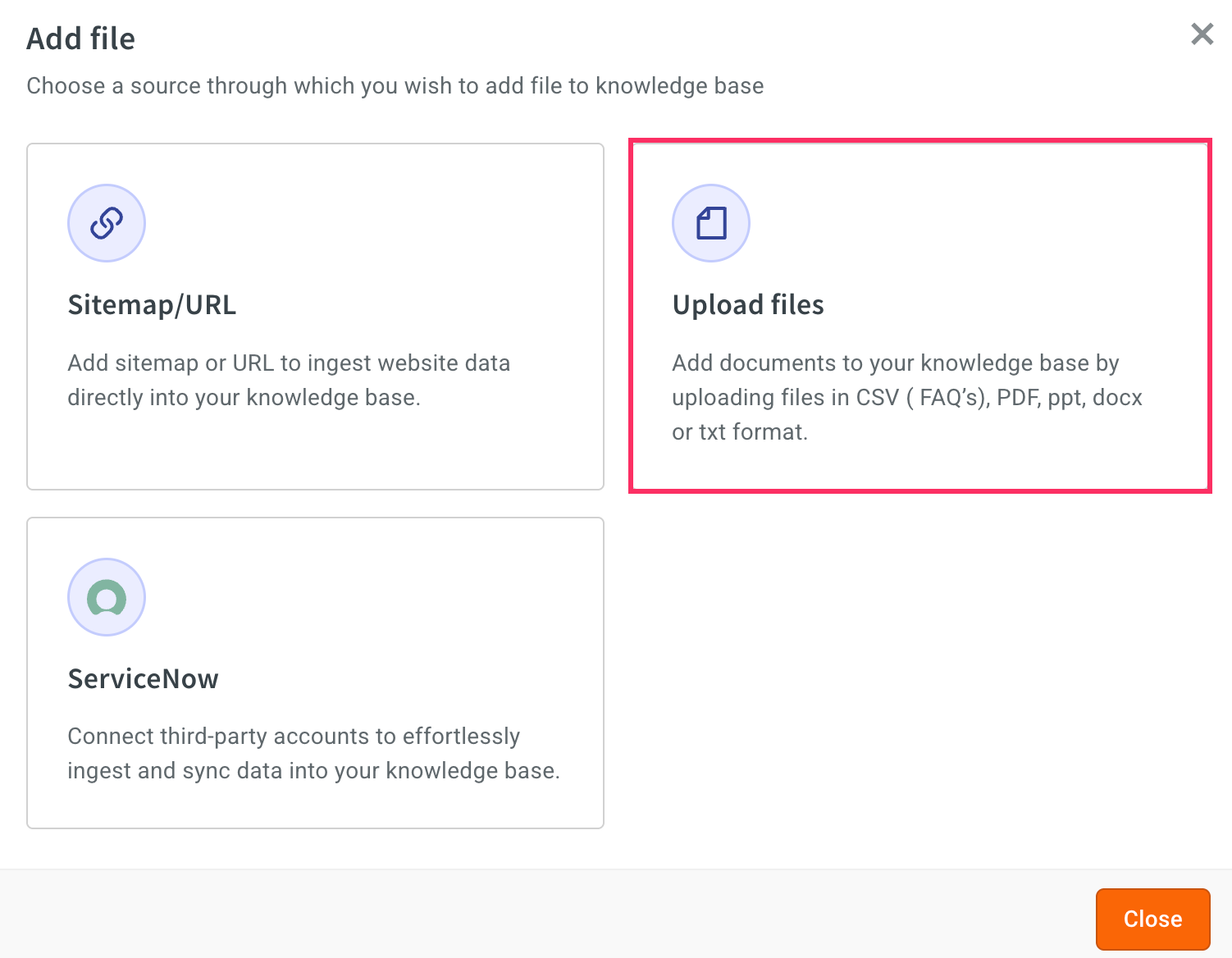
-
Select the file type that you want to upload and click Next.
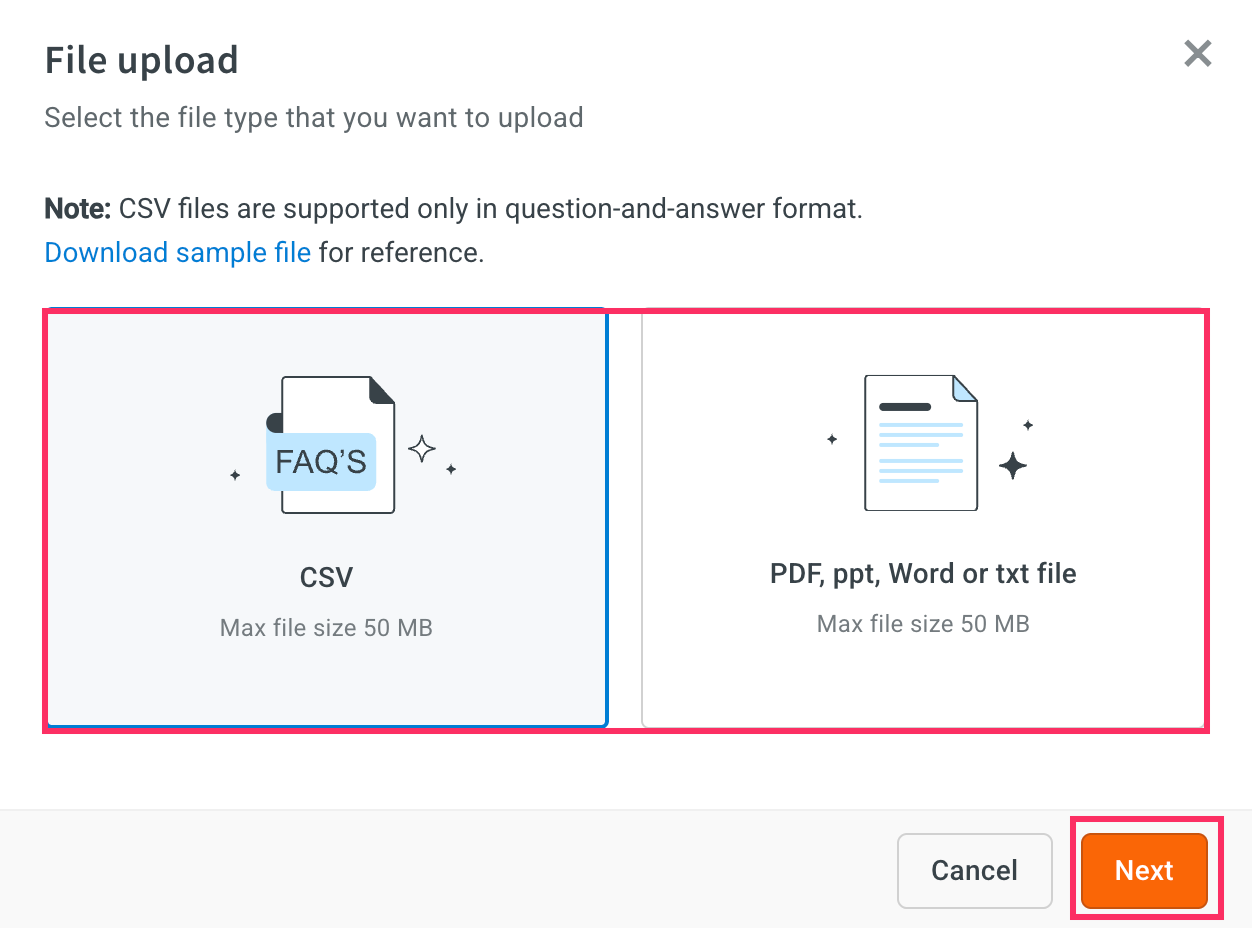
-
Upload the file and click Add document.
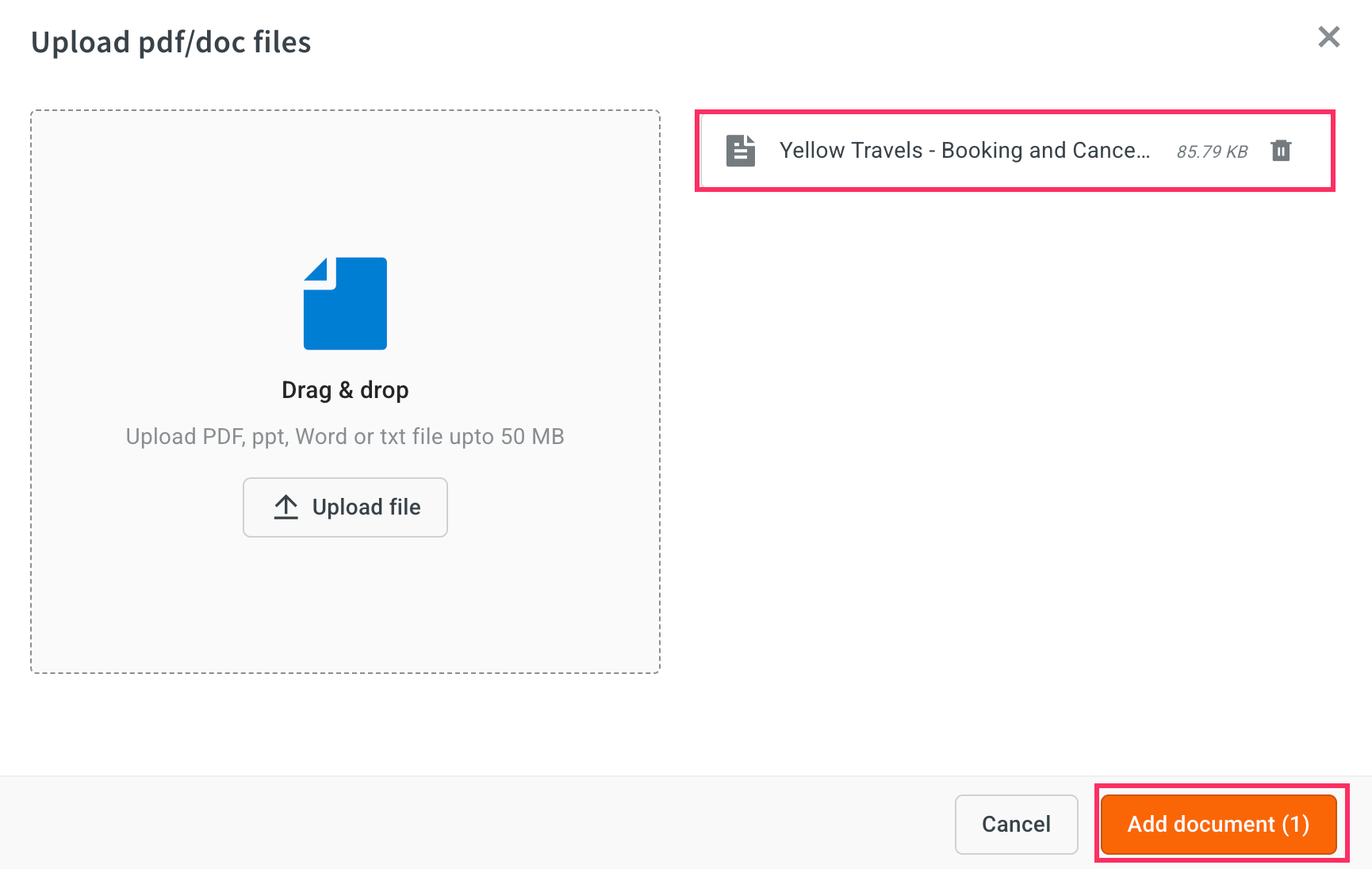
- The document will be uploaded successfully.
-
Go to Test suites and click Generate QnA.
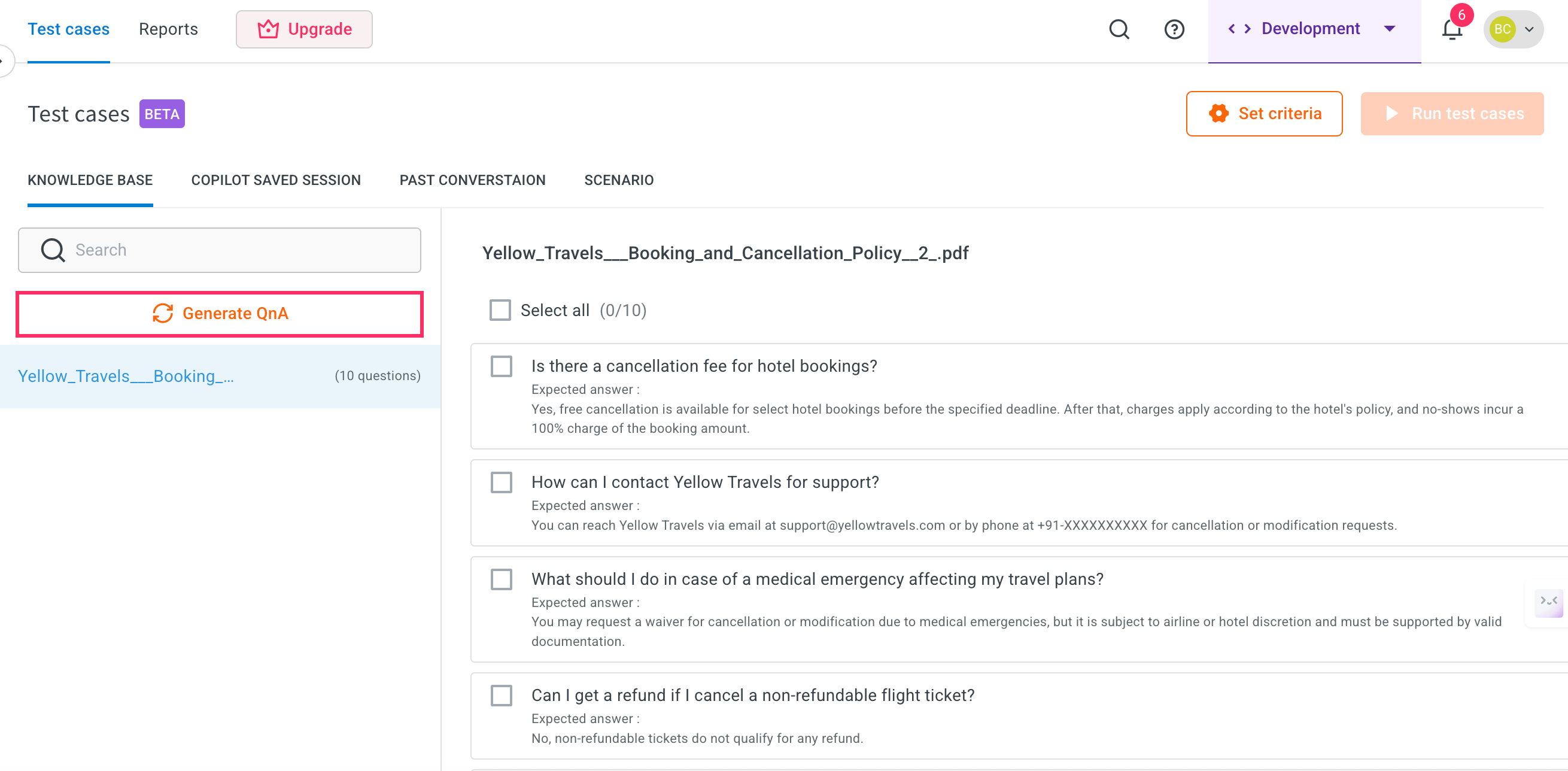
- FAQs will be generated for each uploaded document. You can generate FAQs for up to 100 documents at once.
Configure Set criteria for Knowledge base
After generating the test cases, you need to configure set criteria to define how the test should be evaluated.
To configure set criteria, follow these steps:
-
Click Set criteria.
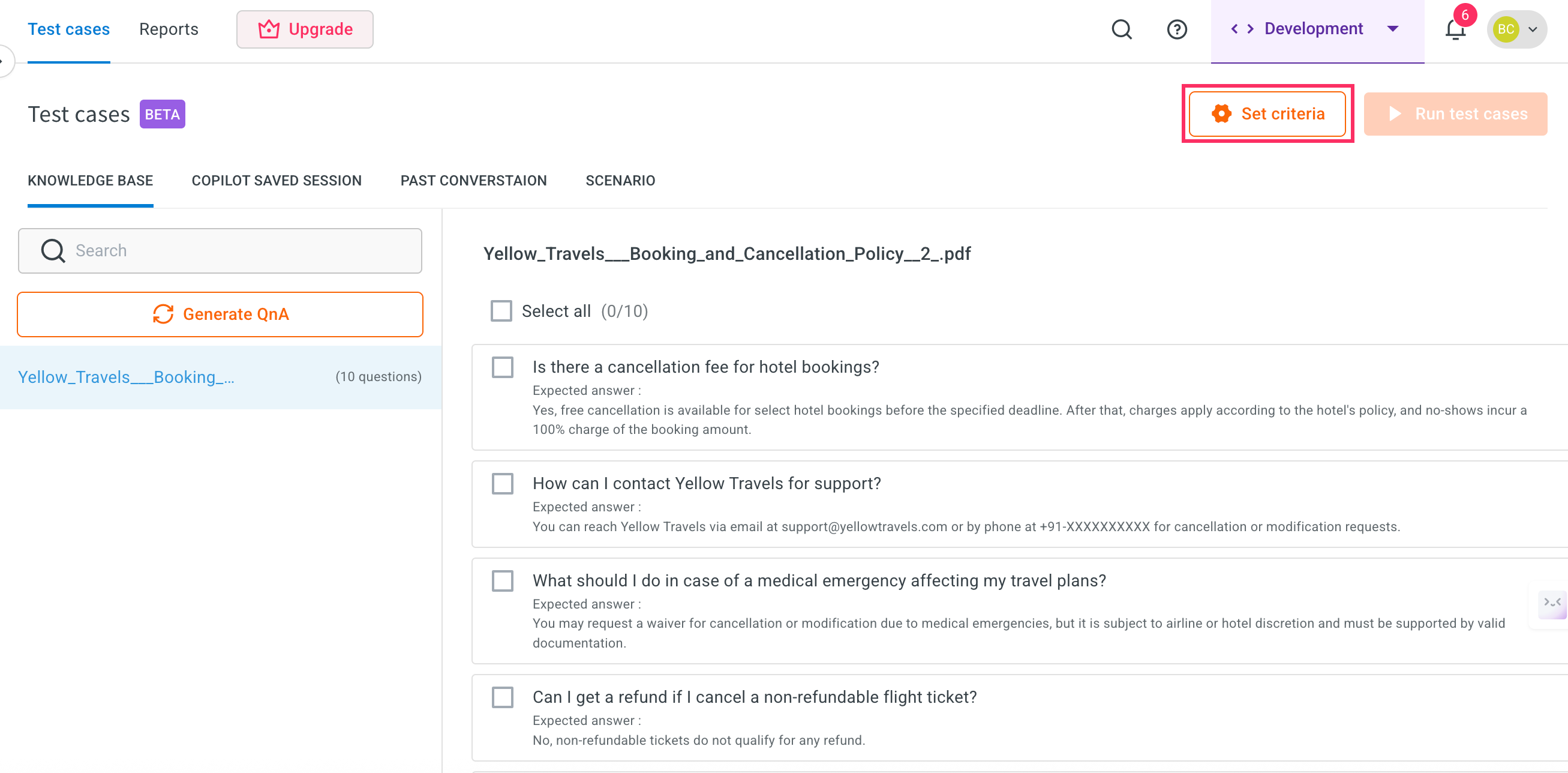
-
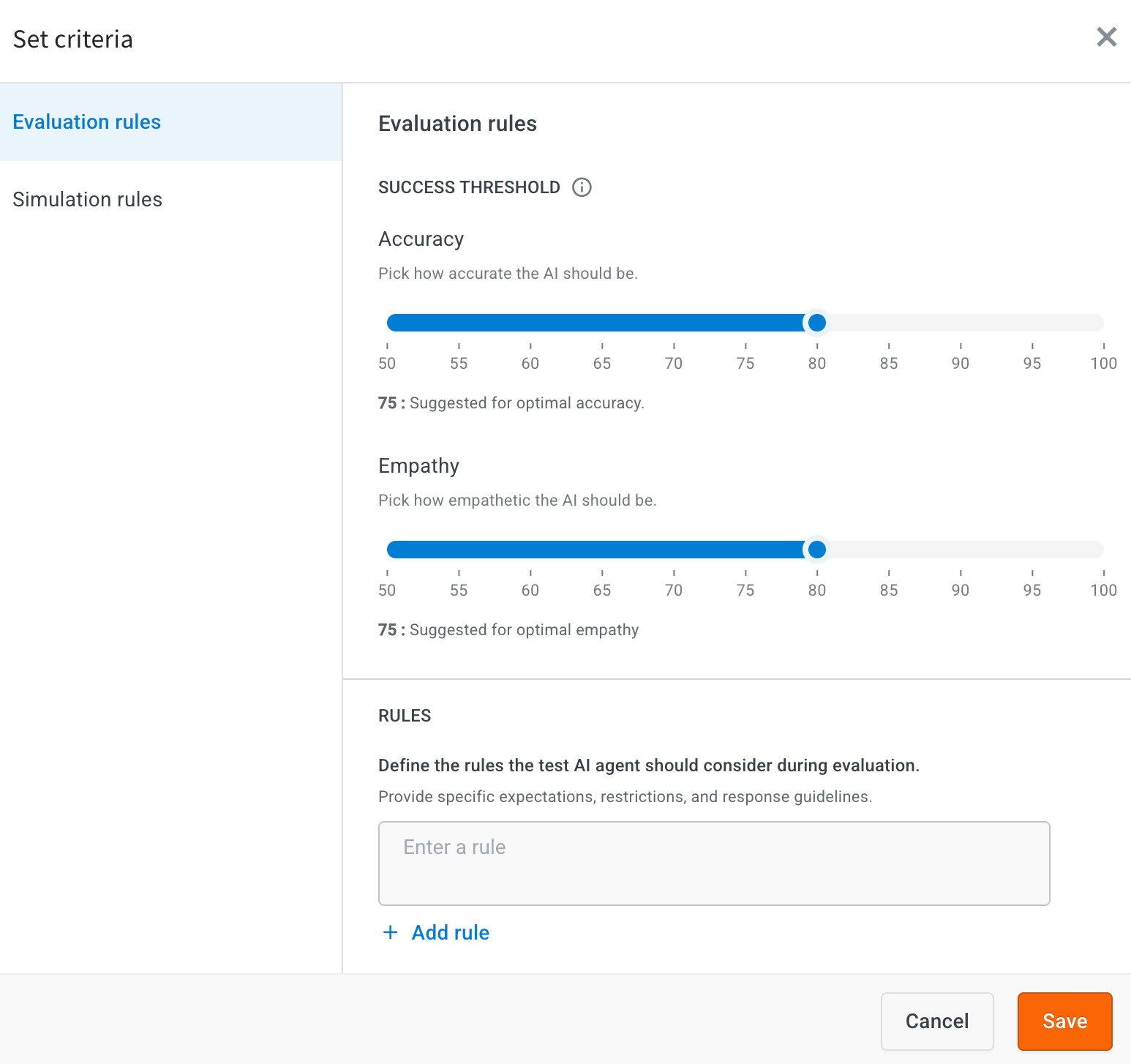
Set the Evaluation rules and click Save.
i. Accuracy: Set the empathy level on the slider. This determines how the AI agent's responses match the expected behavior.
Value: 75 – This is the suggested setting for optimal empathy. ii. Empathy: Set the empathy level on the slider. It ensures the AI responds in a friendly, human-like manner.
Value: 75 – This is the suggested setting for optimal empathy. iii. Rules: Define rules that the AI agent should follow during test case evaluation.
Example- Your questions must be phrased differently and varied each time to make it human-like. Each step should have actionable questions.
- If the user expresses anger or frustration immediately skip to cancellation.
-
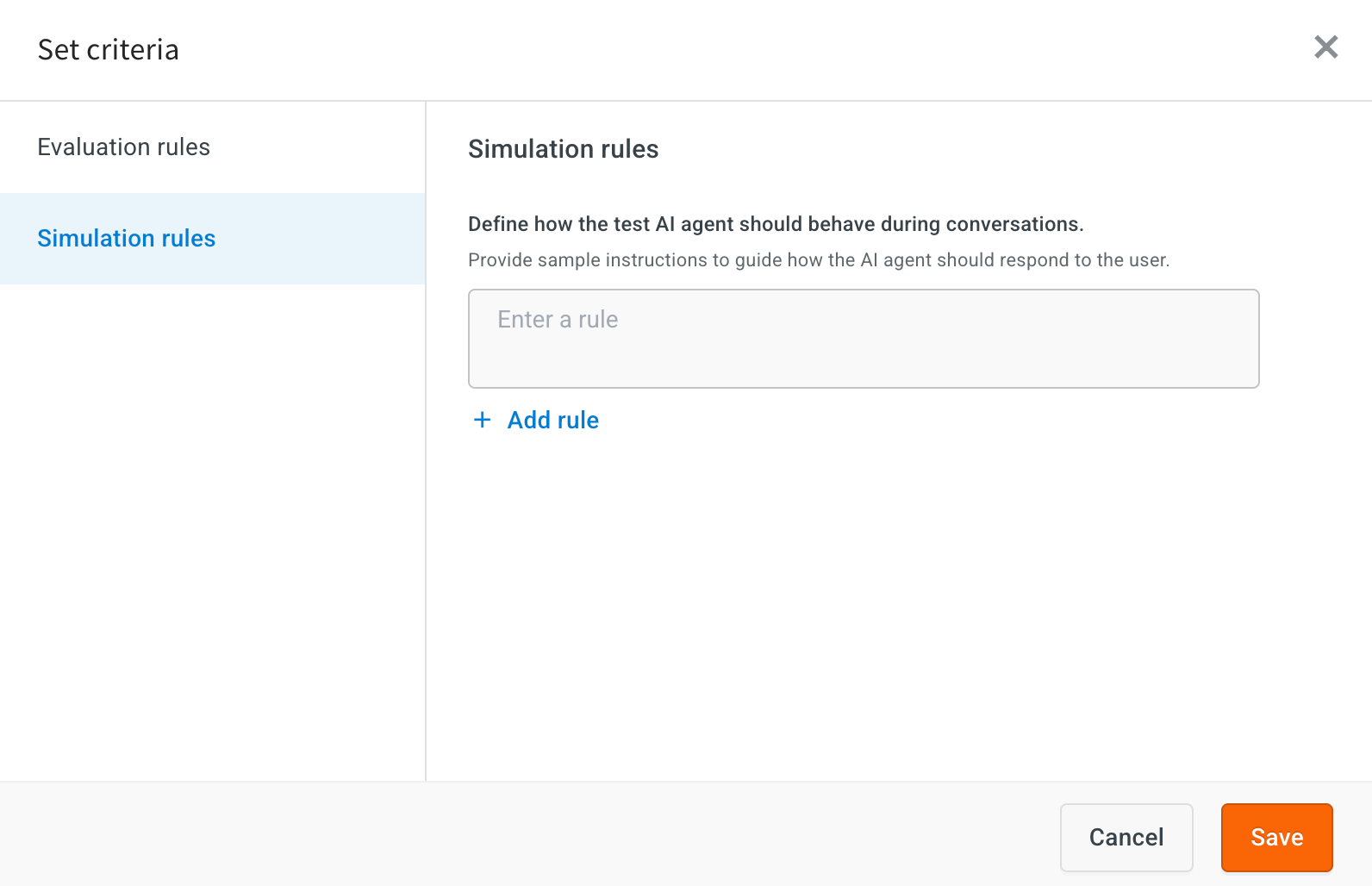
Set Simulation rules: Add the rules to guide how the AI simulates user interactions during testing.
-
If the user provides incomplete information, simulate a natural follow-up question instead of re-asking the original question.
-
Always rephrase questions in a human-like manner to avoid repetition and mimic natural conversation patterns.
-
Run a test case for Knowledge base
To run a test case, follow these steps:
-
Go to the list of generated Knowledge Base test cases. Use the checkboxes to select one or more test cases you want to execute.
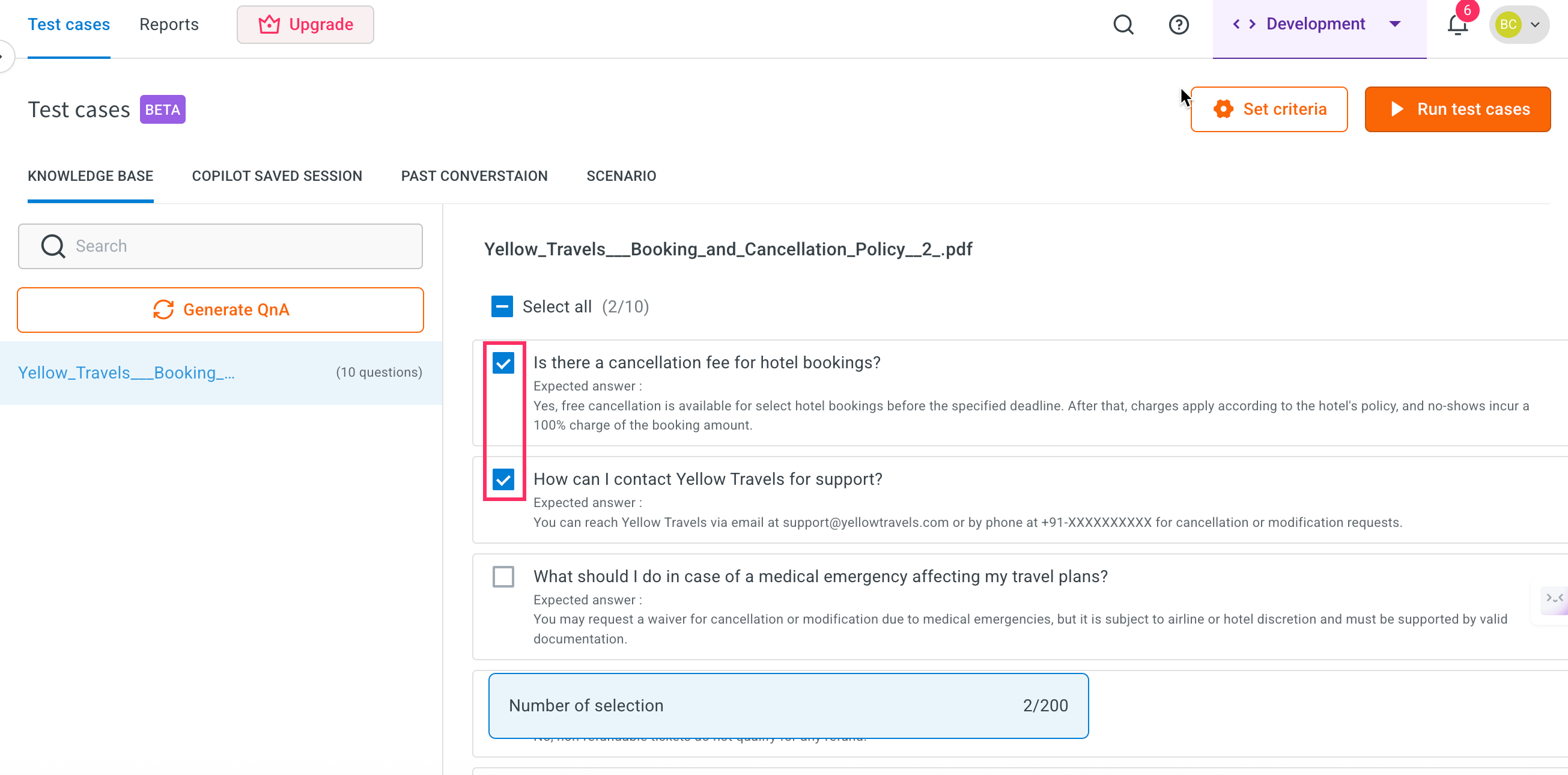
-
Click Run test cases button at the top.
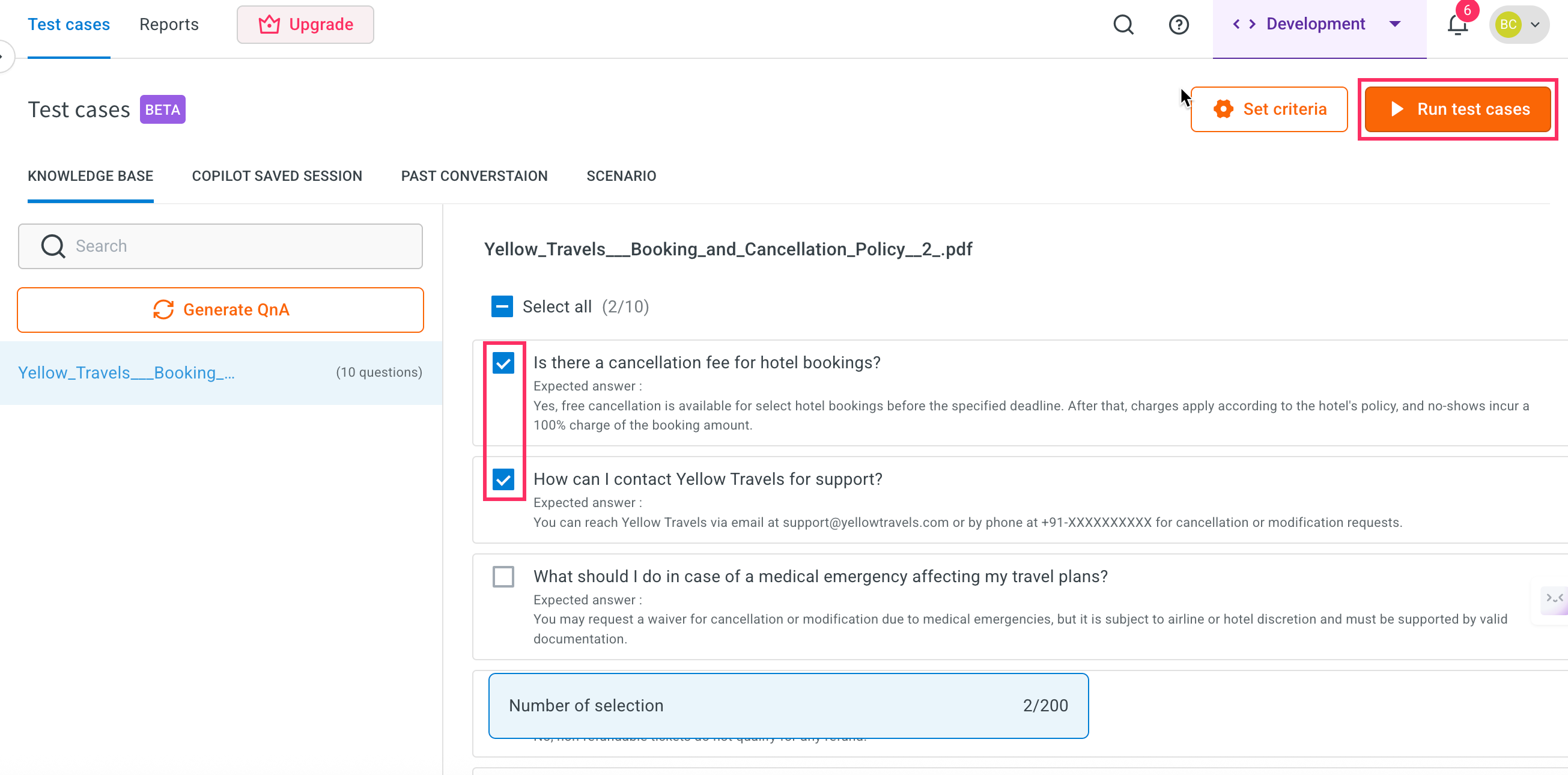
-
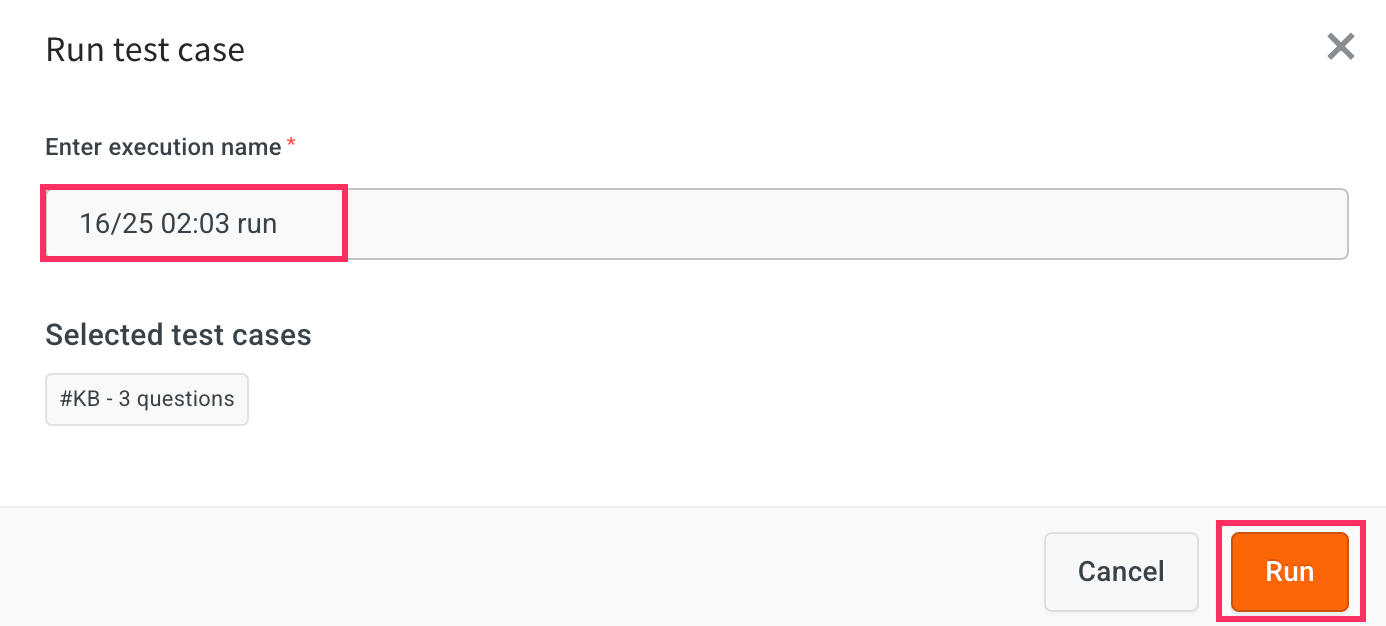
Enter a Execution name and click Run. Note that, by default execution name will be displayed based on date and time.
-
Click Check reports to view the results of the test case executions.
-
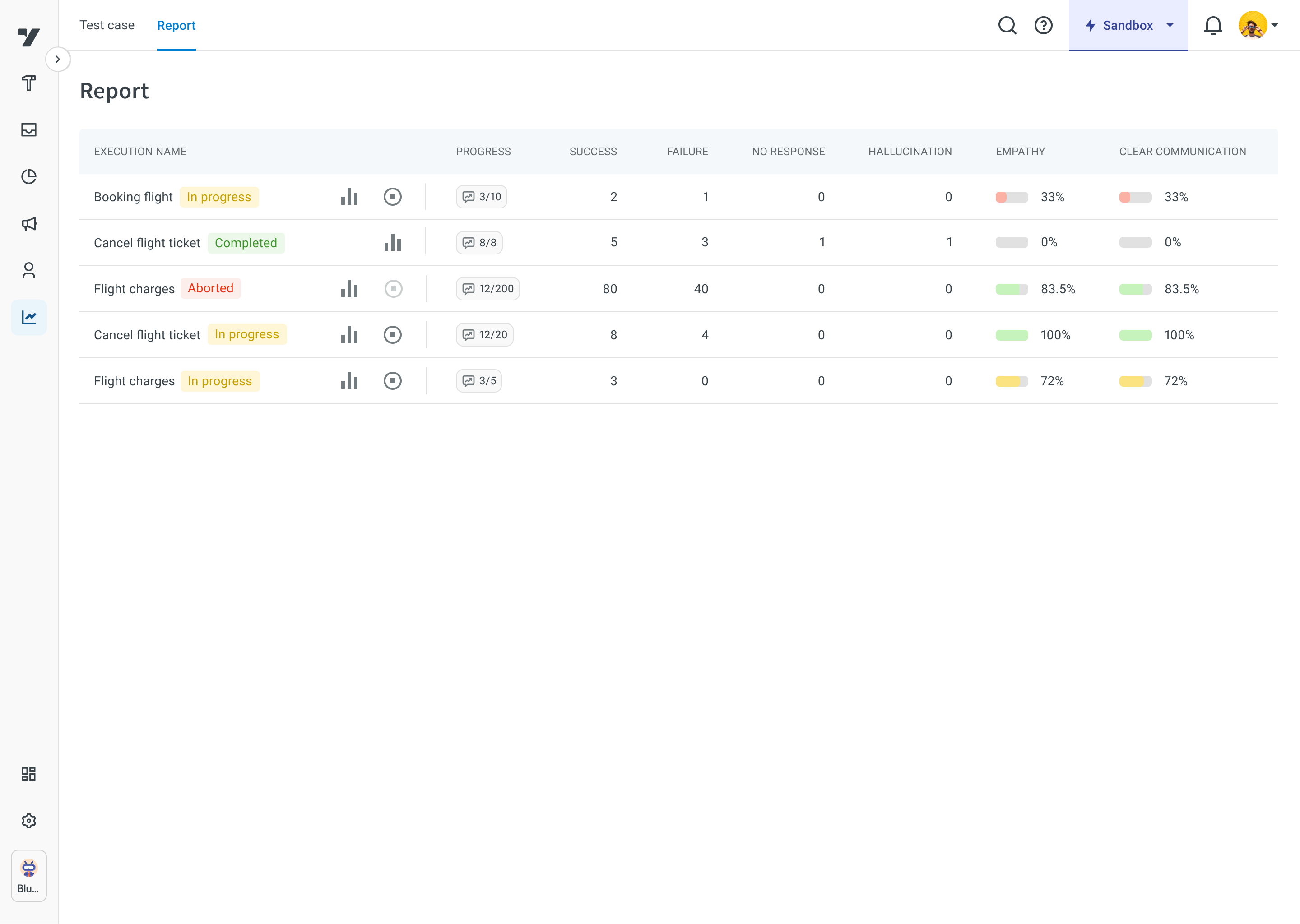
In the Report section, you can view the status of each test case along with details like the accuracy score, empathy score, and whether the AI response meets your configured rules.
View Knowledge base report
You can view the detailed results of each test case and compare actual versus expected outcomes.
To view report, follow these steps:
-
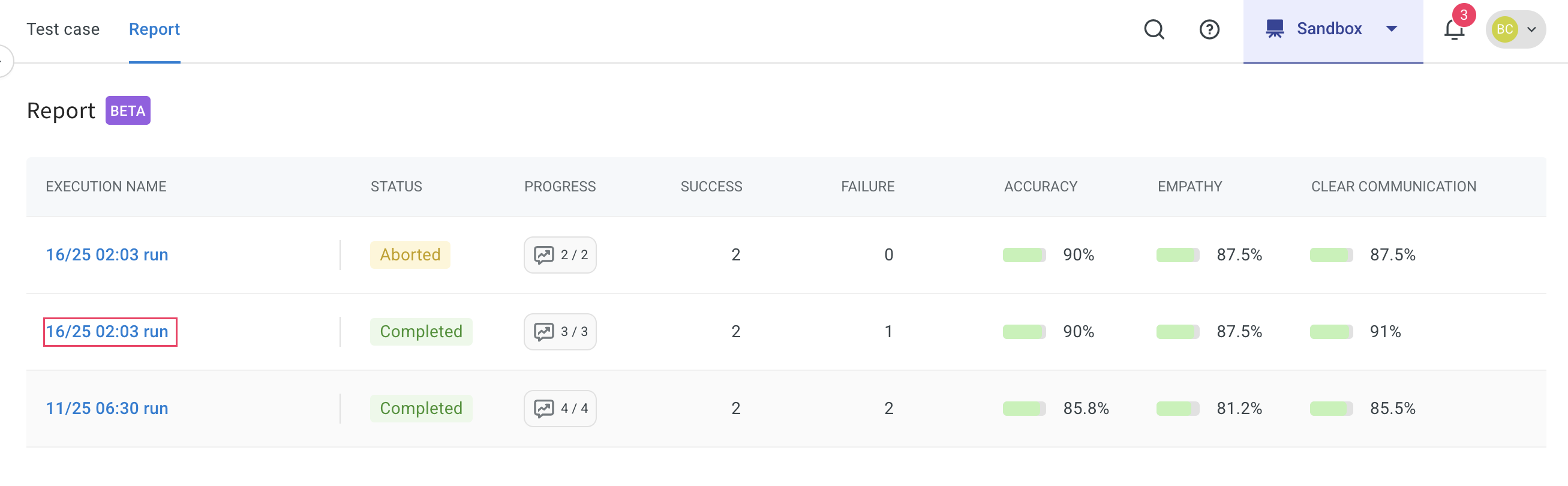
Click the Execution name link.
-
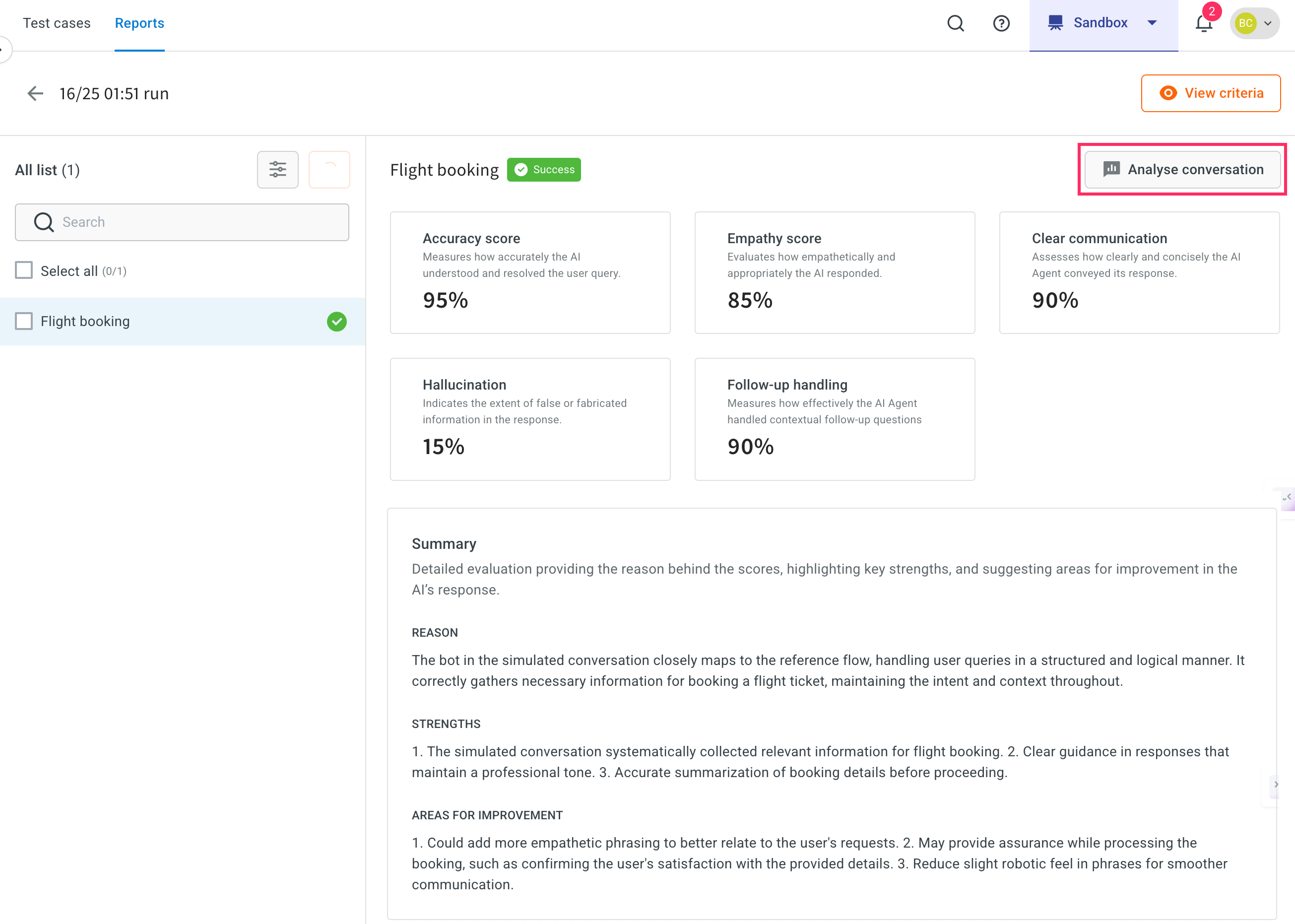
Here, you can view the complete status of the report. This report contains Accuracy score, Empathy score, clear communication, Hallucination, and Follow-up handling.
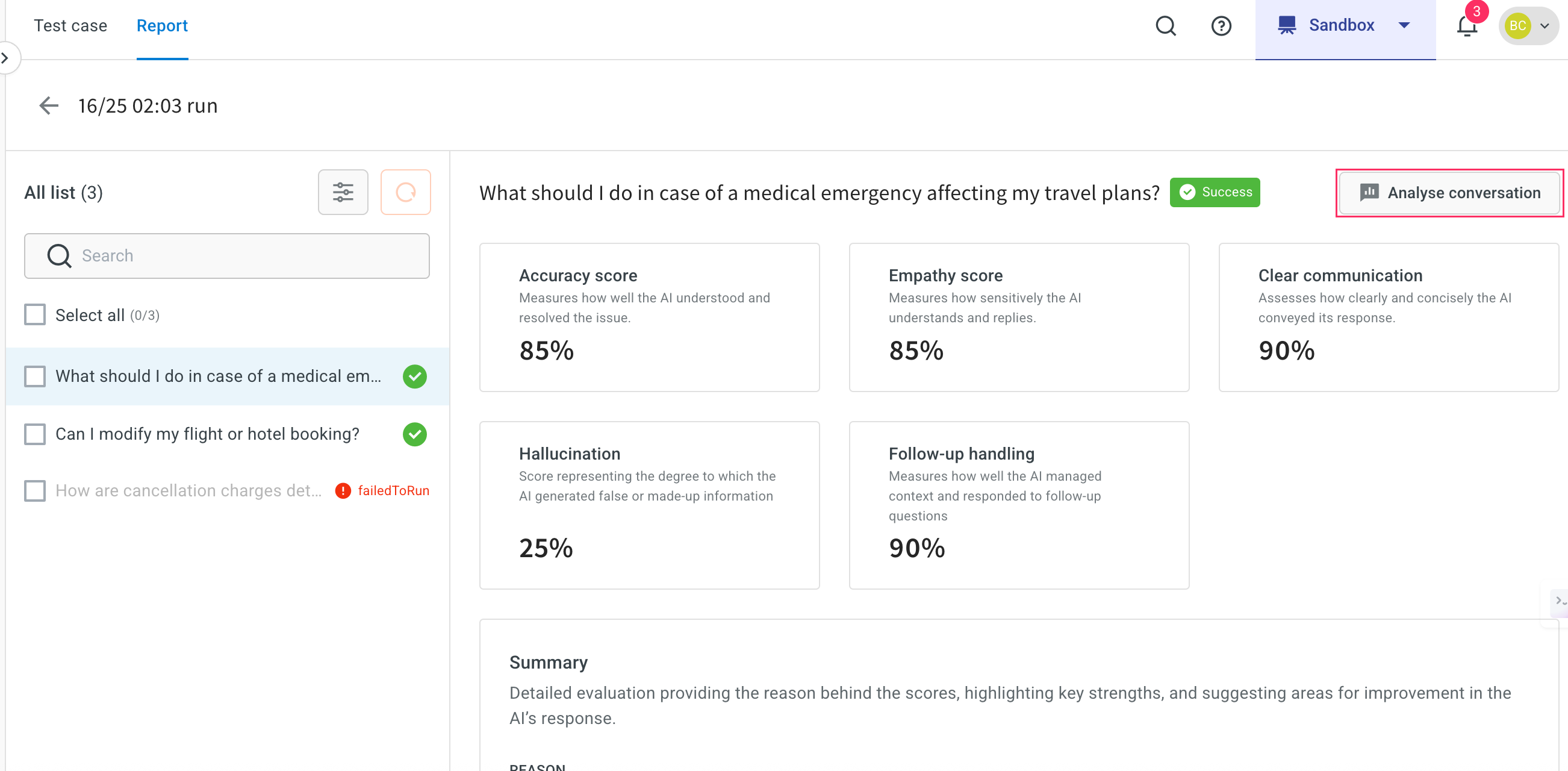
-
Click Analyse conversation to compare the expected FAQ and the agent’s response during simulation.
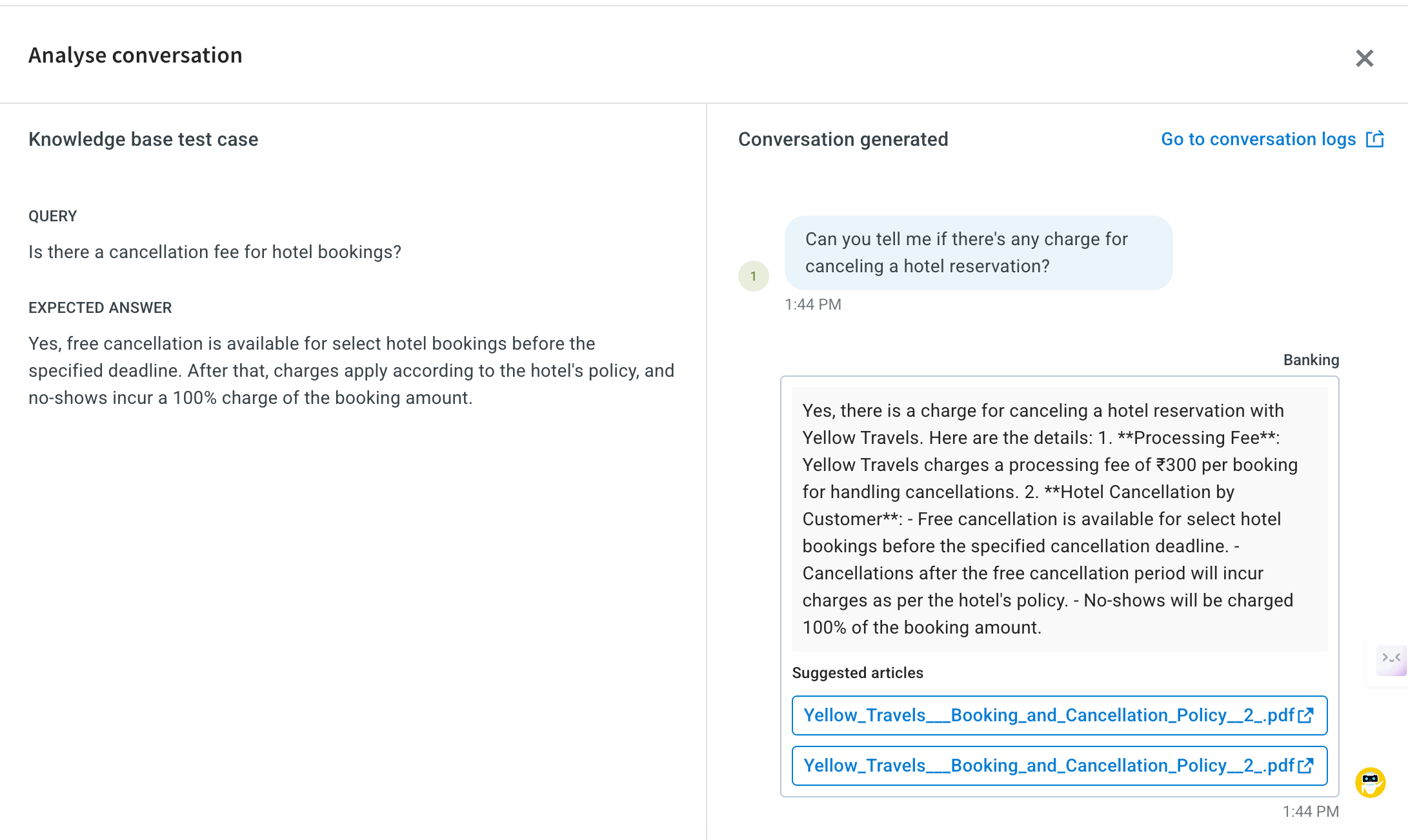
Test Copilot saved session
You can test your AI agent using saved conversations from Copilot.
To create and validate a Copilot saved session, follow these steps:
-
Navigate to Automation > Test suites.
-
Click on Copilot saved session, then select Go to Copilot to begin creating the test case.
- This will navigate you to the Copilot module.
-
In Copilot, click Begin with fresh conversation to initiate a new test session.
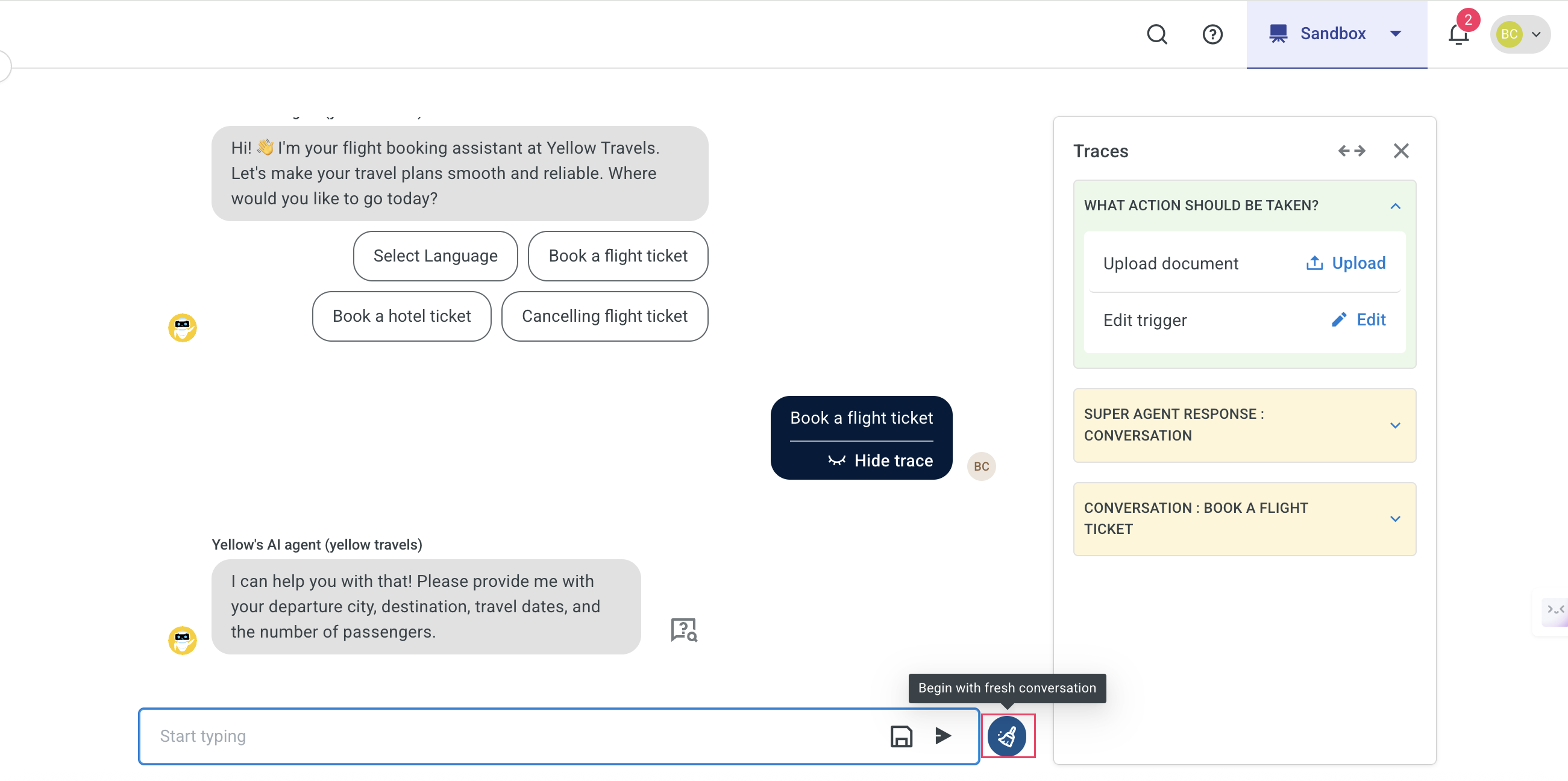
-
Start the conversation and click Save test case icon to save the session.
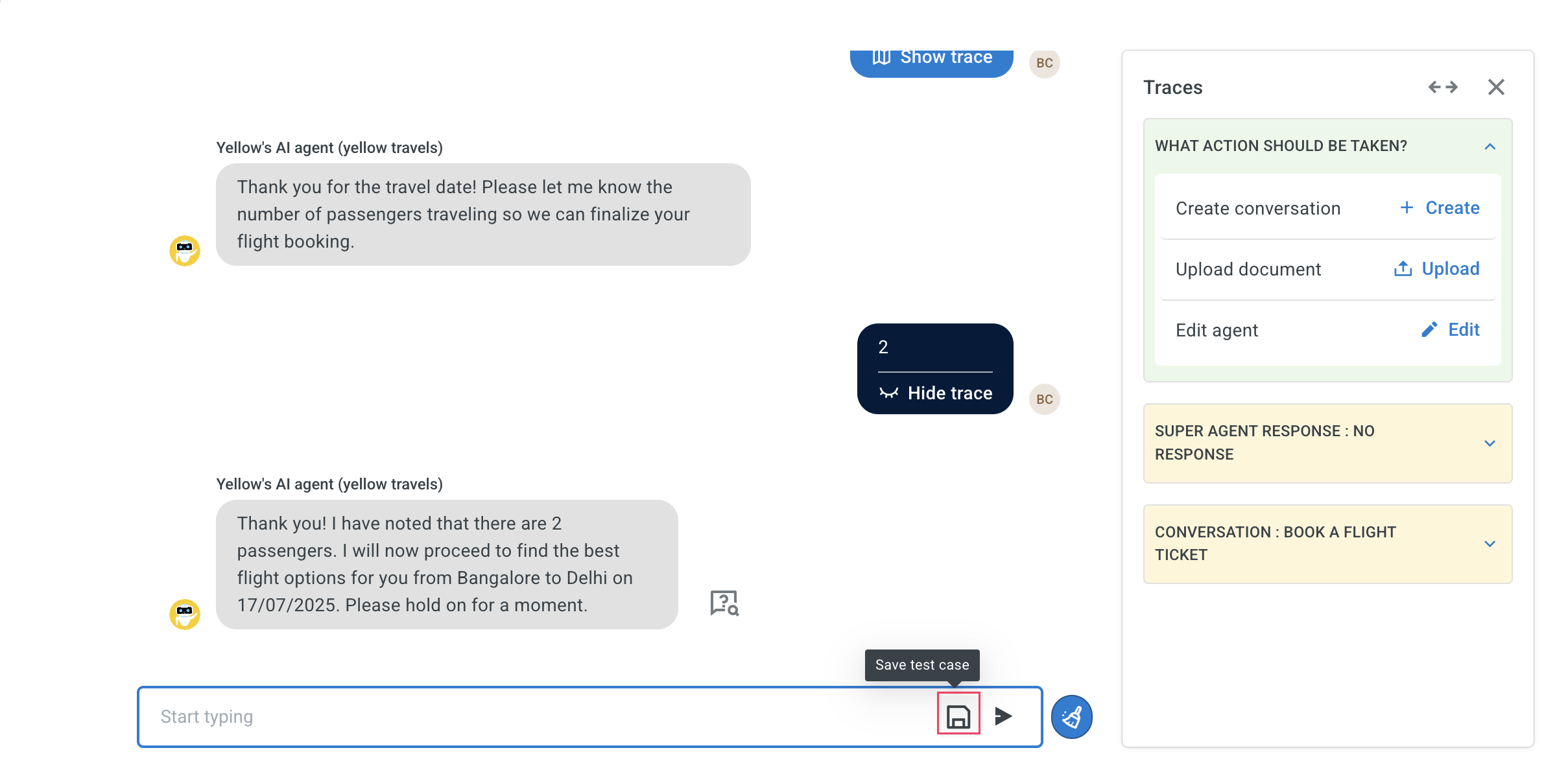
-
Enter a name for your test case and click Save.
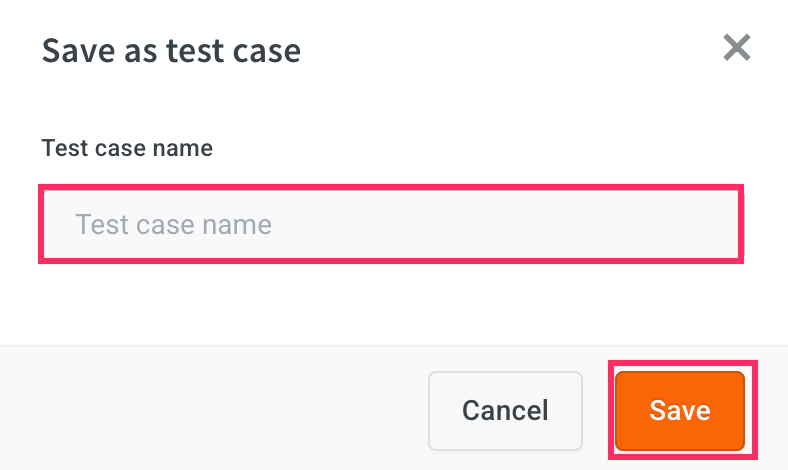
You can save up to 10 pairs of conversation per testcase.
-
Click Check testcase to review your saved conversation. This will display the recorded session under the Copilot saved session tab.
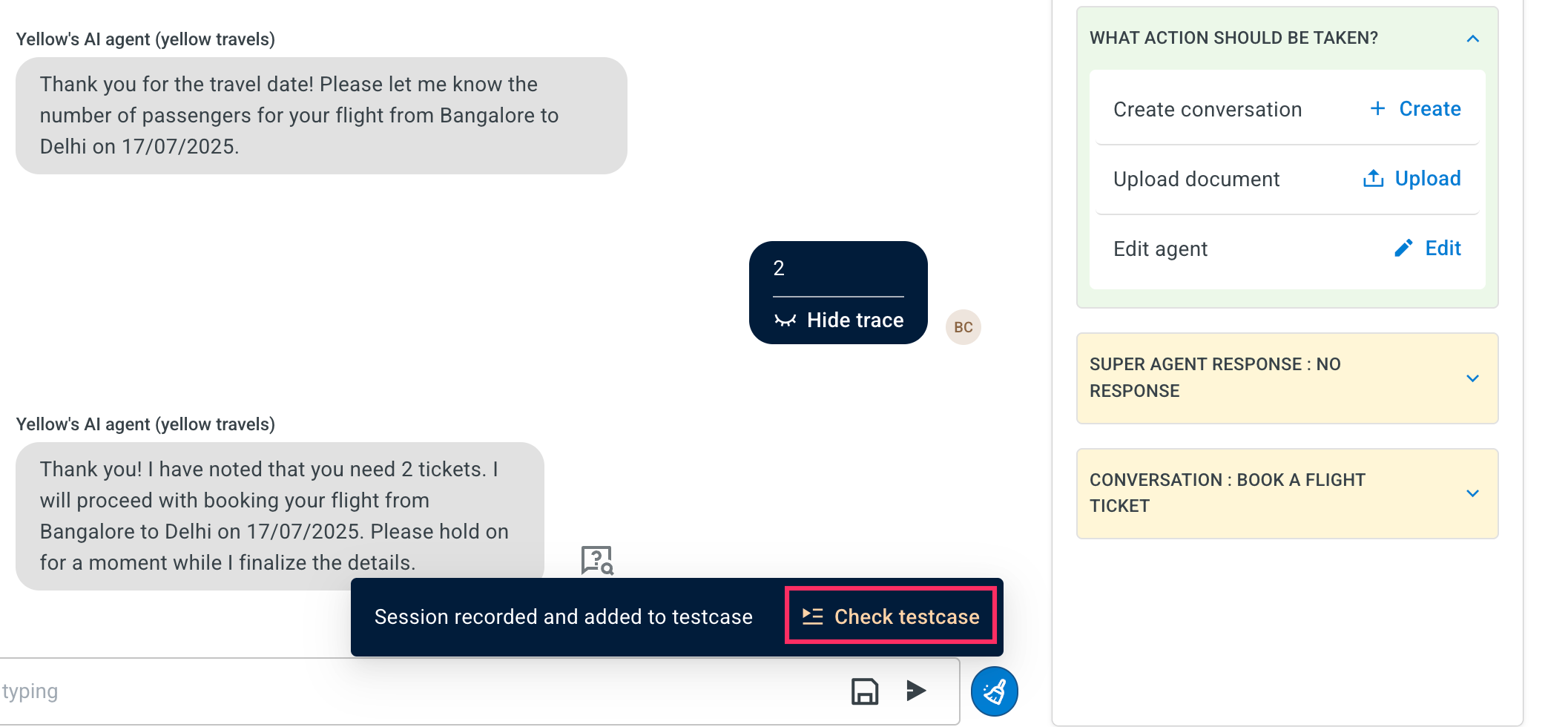
-
The saved session will be displayed in the Copilot saved session tab.
Configure set criteria for Copilot saved session
After saving a test case, you need to configure set criteria to define how the Copilot should evaluate the session. This step helps ensure your AI agent behaves as expected.
To configure set criteria, follow these steps:
-
In the Copilot saved session tab, click on Set criteria for the test case you want to configure.
-
Set the Evaluation rules and click Save.
i. Accuracy: Set the empathy level on the slider. This determines how the AI agent's responses match the expected behavior.
Value: 75 – This is the suggested setting for optimal empathy. ii. Empathy: Set the empathy level on the slider. This ensures the AI responds in a friendly, human-like tone.
Value: 75 – This is the suggested setting for optimal empathy.
iii. Rules: Define rules that the AI agent should follow during test case evaluation.
Example:- Your questions must be phrased differently and varied each time to make it human-like.
- If the user expresses anger or frustration immediately skip to cancellation.
-
Set Simulation rules: Add the rules to guide how the AI simulates user interactions during testing.
-
If the user provides incomplete information, simulate a natural follow-up question instead of re-asking the original question.
-
Always rephrase questions in a human-like manner to avoid repetition and mimic natural conversation patterns.
-
Run a test case for Copilot saved session
To run a test case for Copilot saved session, follow these steps:
-
Go to the Copilot saved session tab. Use the checkboxes to select one or more test cases that you want to run.
-
Click Run test cases button at the top.
-
Enter an Execution name for the test run. By default, the name will be auto-filled based on the current date and time.
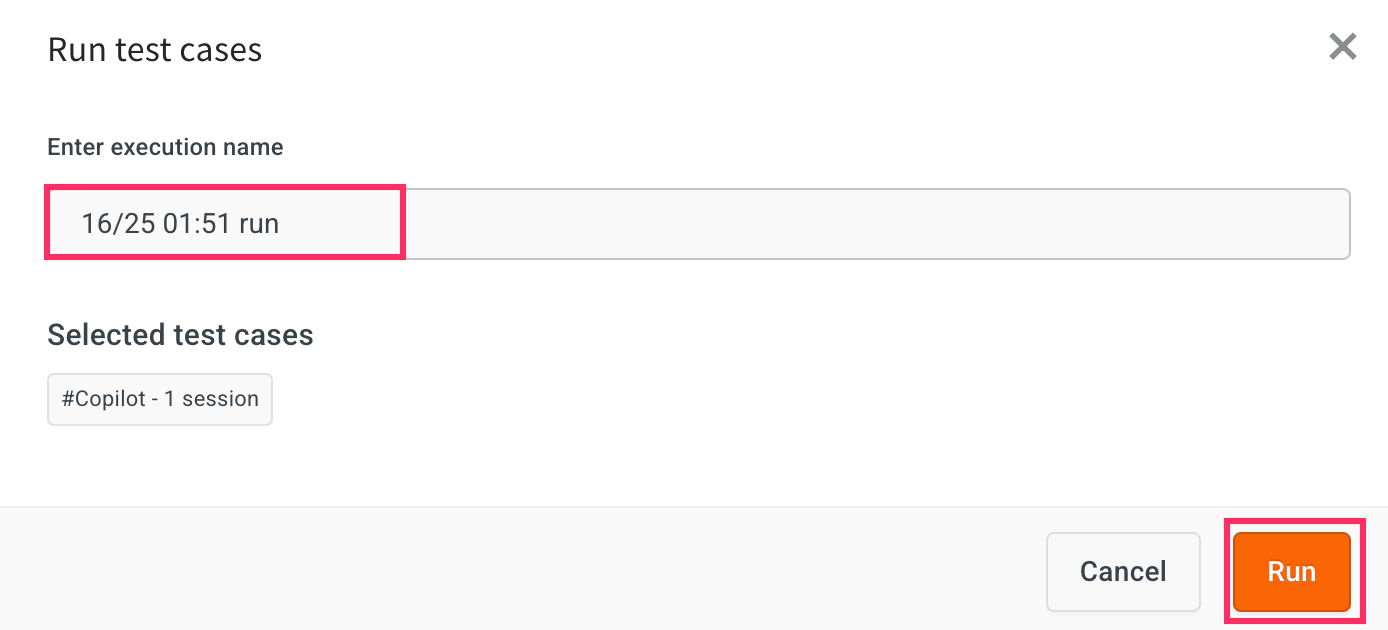
-
Click Run to start the test execution.
-
Click Check reports to view the results of the test case execution.
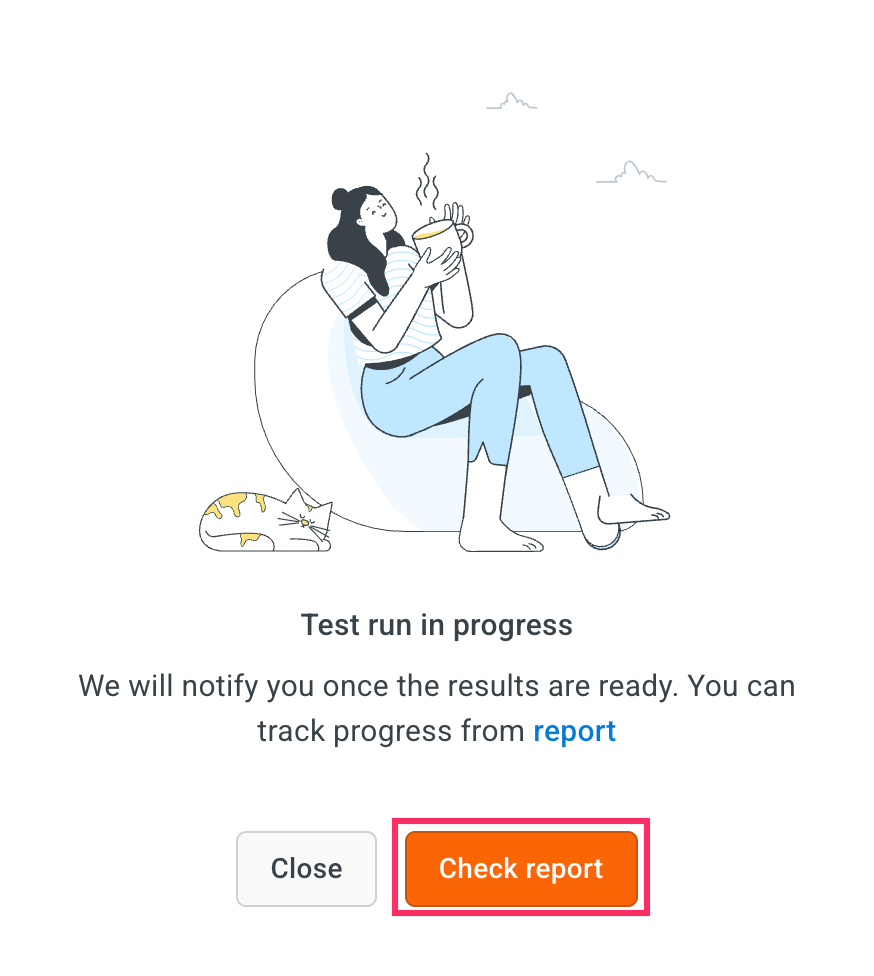
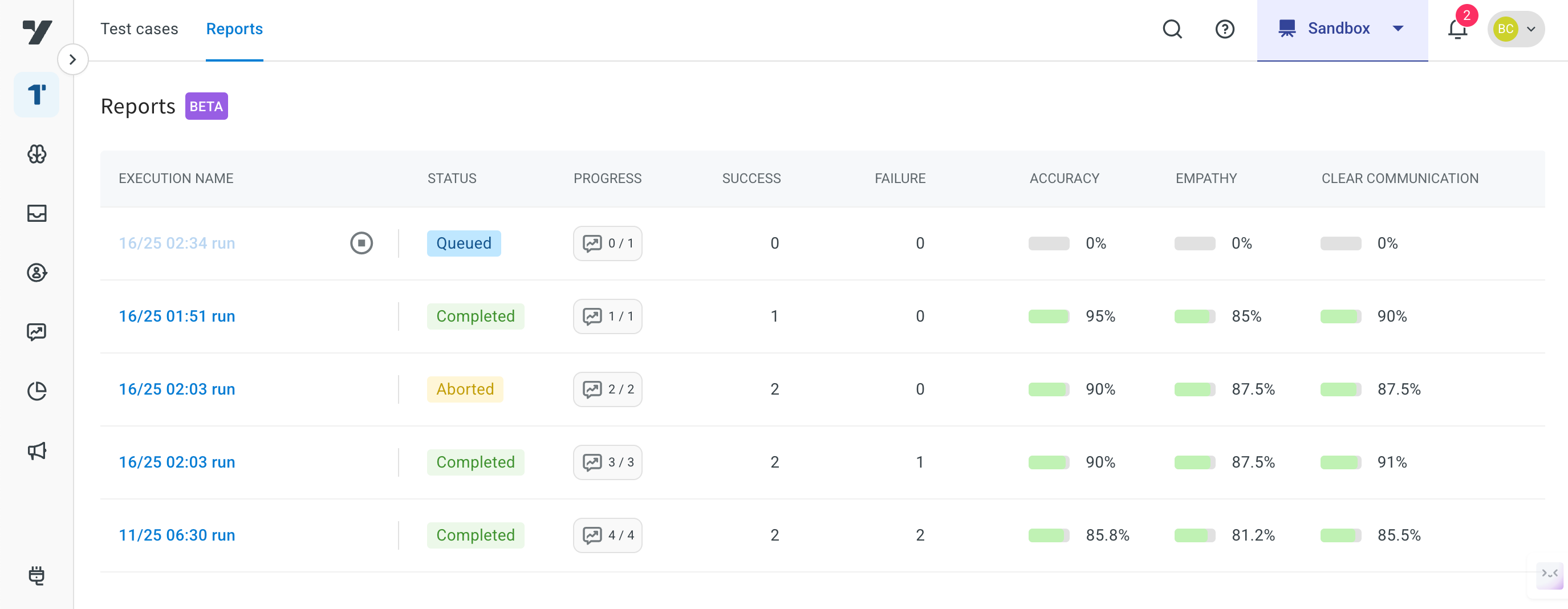
- In the Report section, you will see a summary of the test execution, including:
- Status (Passed/Failed)
- Accuracy Score
- Empathy Score
- Compliance with evaluation rules and simulation behavior
View report of Copilot saved session
After running a Copilot saved session test, you can view detailed reports to evaluate how the AI agent performed compared to expected behavior.
To view report, follow these steps:
-
Click the Execution name link.
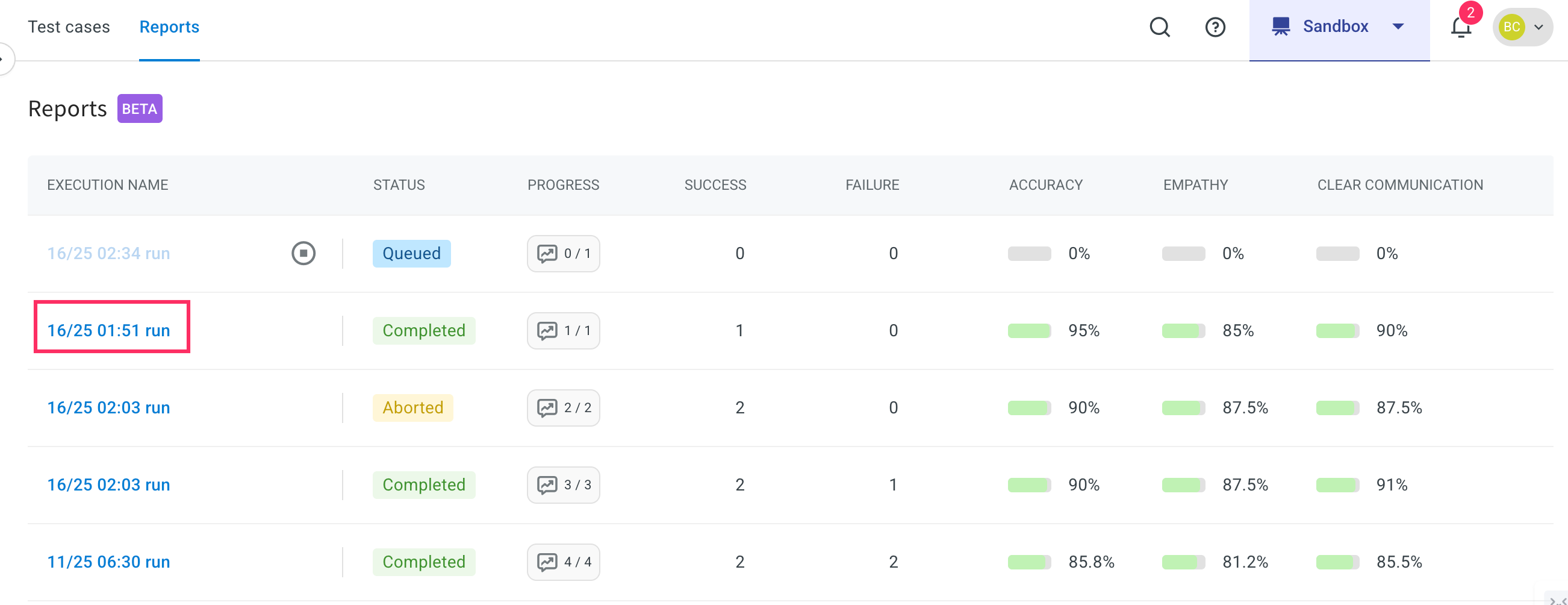
- Here, you can view the complete status of the report. This report provides a comprehensive overview of the AI agent's performance, including:
- Accuracy score
- Empathy score
- Clear communication
- Hallucination
- Follow-up handling.
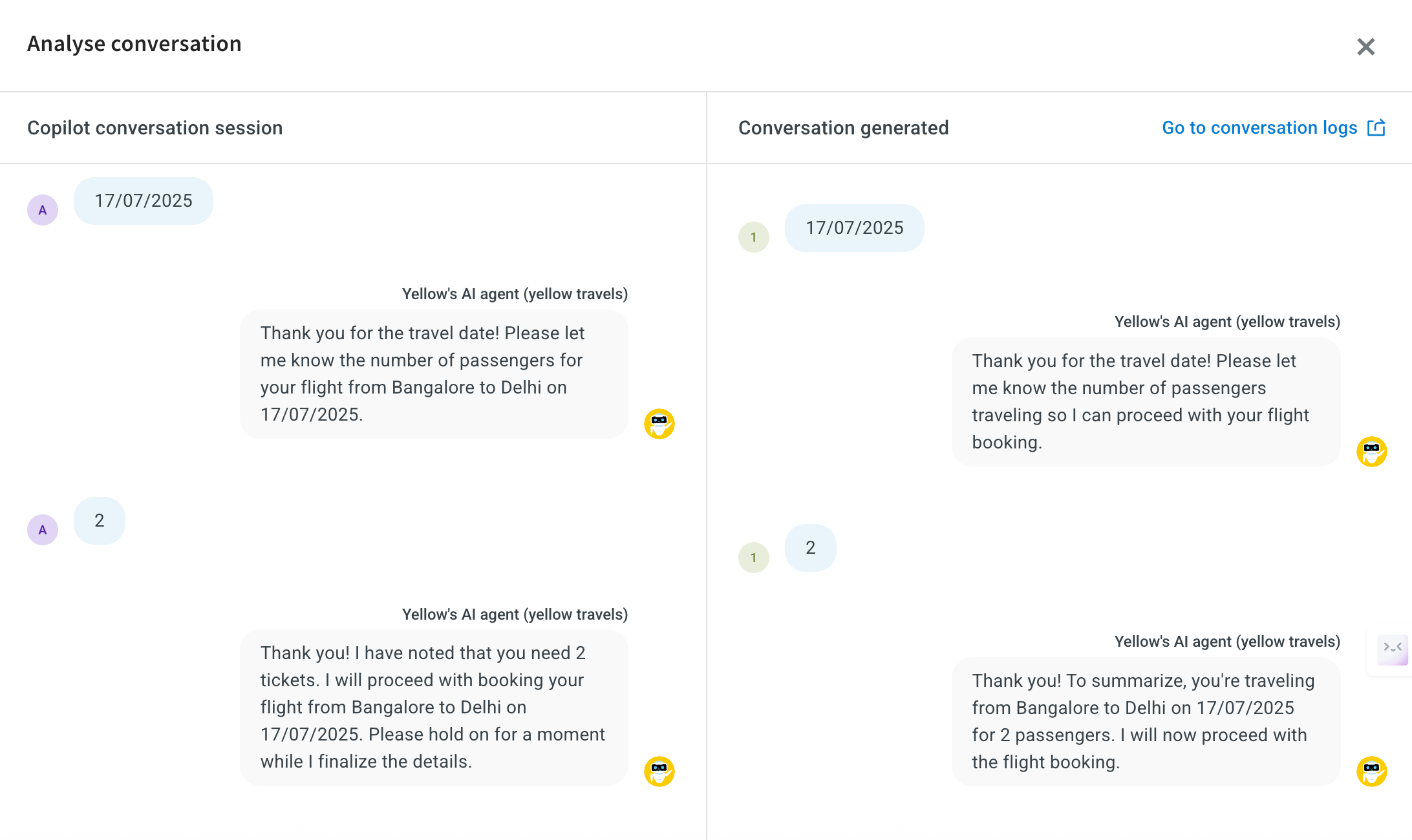
- Click on Analyse conversation to open a side-by-side view of:
- The Copilot conversation session (test input and expected flow)
- The Simulated agent response (what actually happened during the test)
This allows you to compare expected vs actual behavior and ensures if the AI handled the conversation correctly.
Scenario based testing
Prerequisites
- You need to create an agent before starting scenario-based testing.
- Test scenarios can only be generated if your agent has configured start trigger or prompt. If your agent is created without these configurations, the Generate button will be disabled.
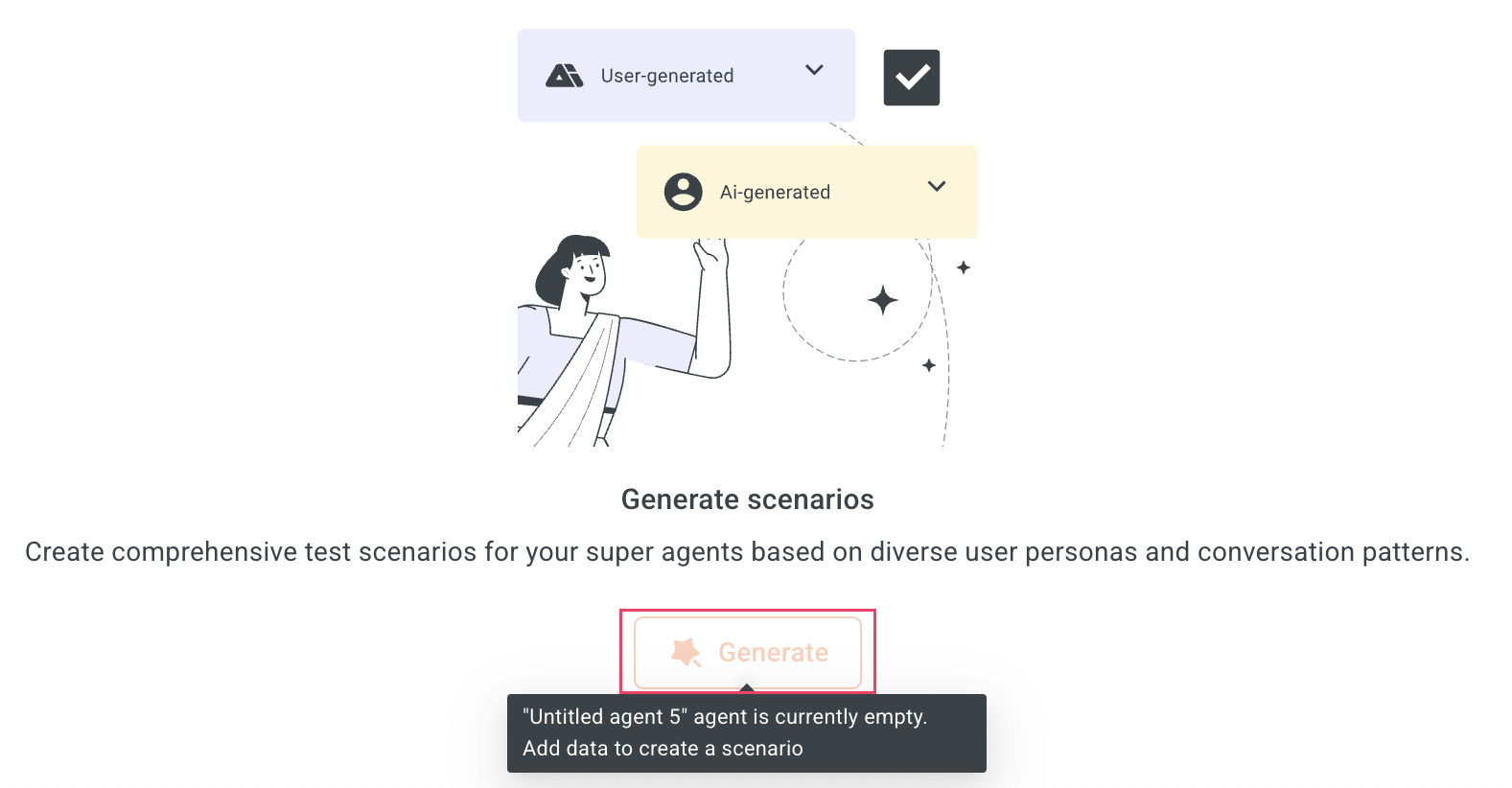
To test a scenario, follow these steps:
-
Navigate to Automation > Test suites.
-
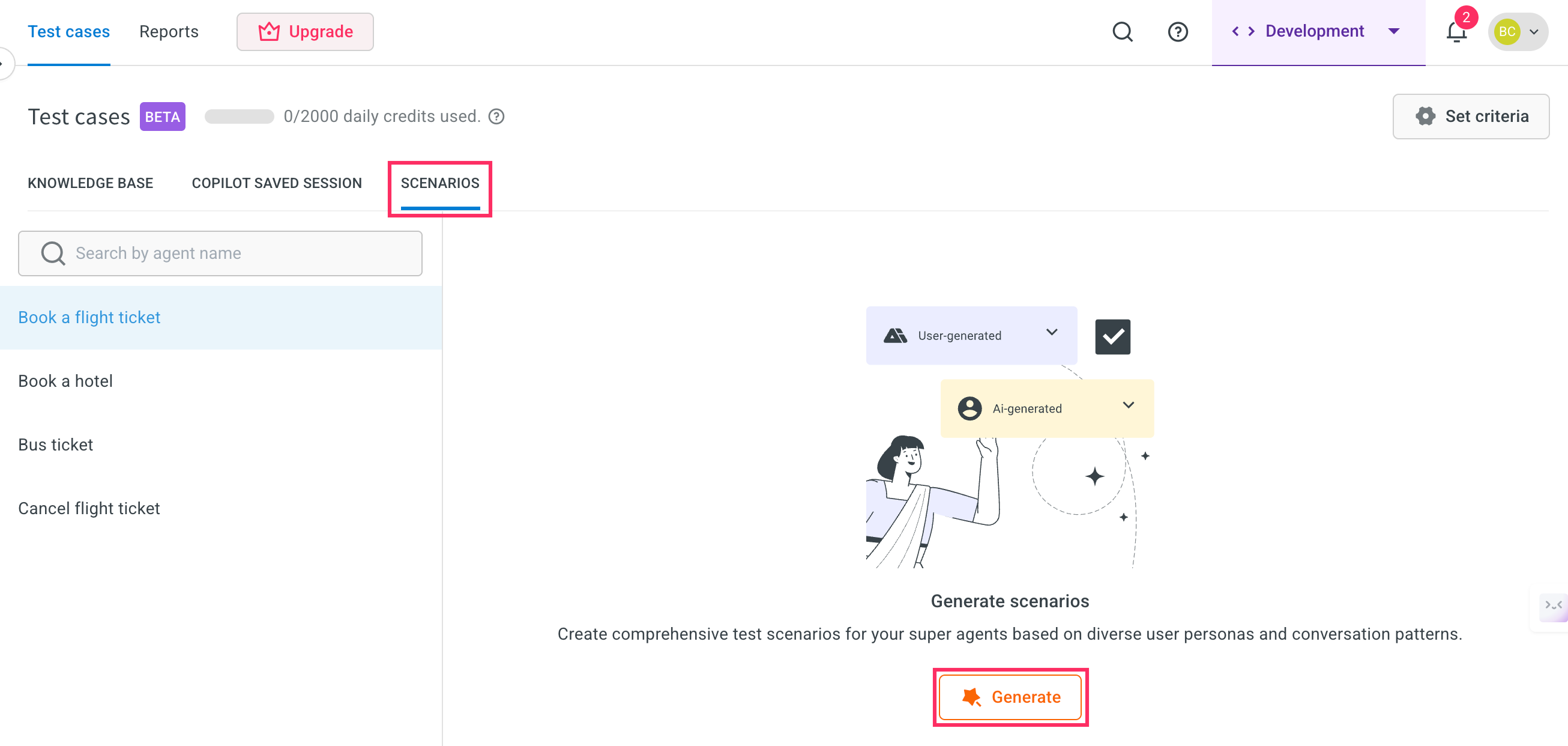
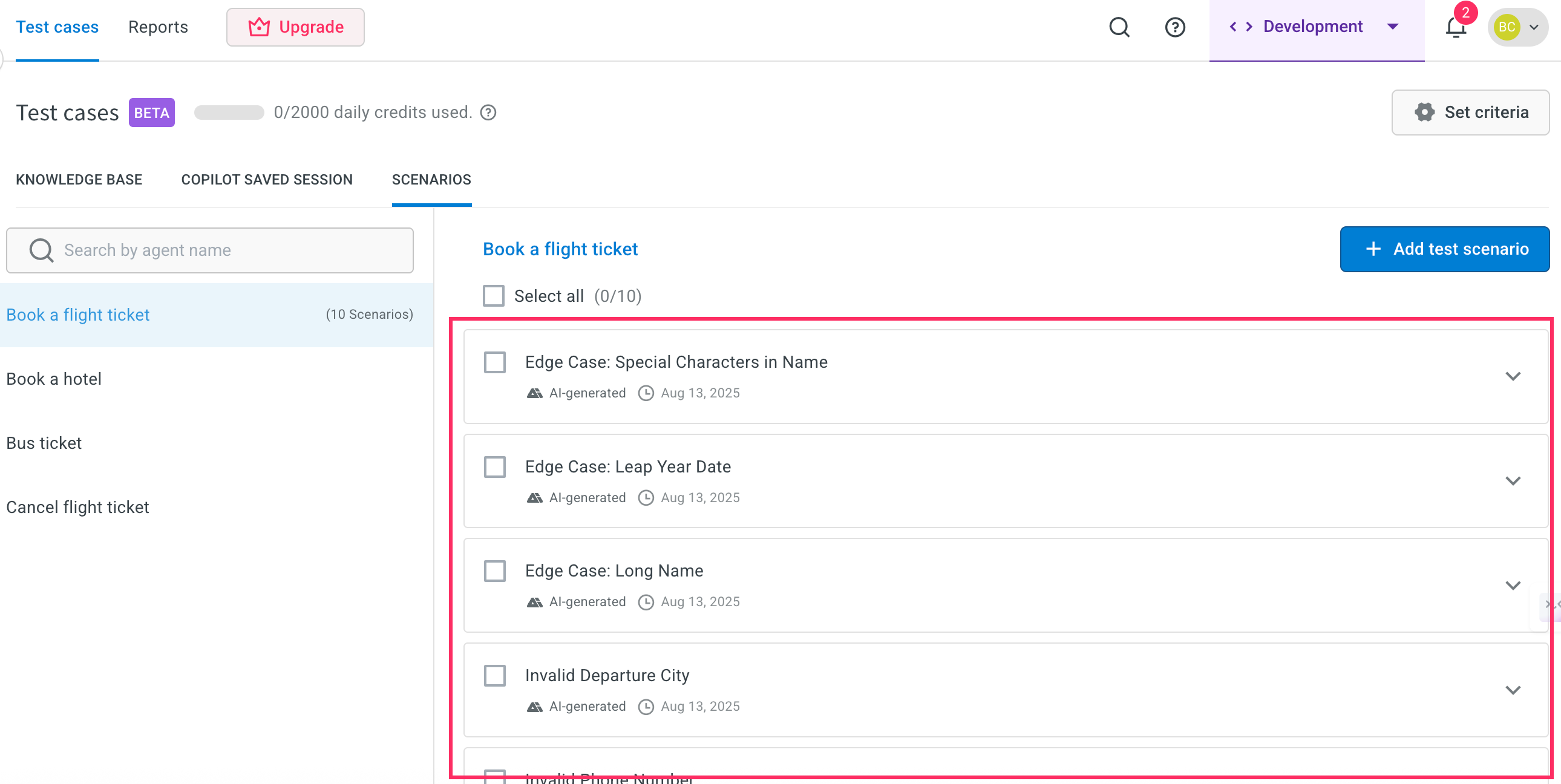
Click on Scenarios > Test cases > Generate to create a list of test cases.
-
A maximum of 10 scenarios will be generated per agent.
Configure Set criteria for scenario-based test case
After generating test case, you need to configure Set criteria.
To configure set criteria, follow these steps:
-
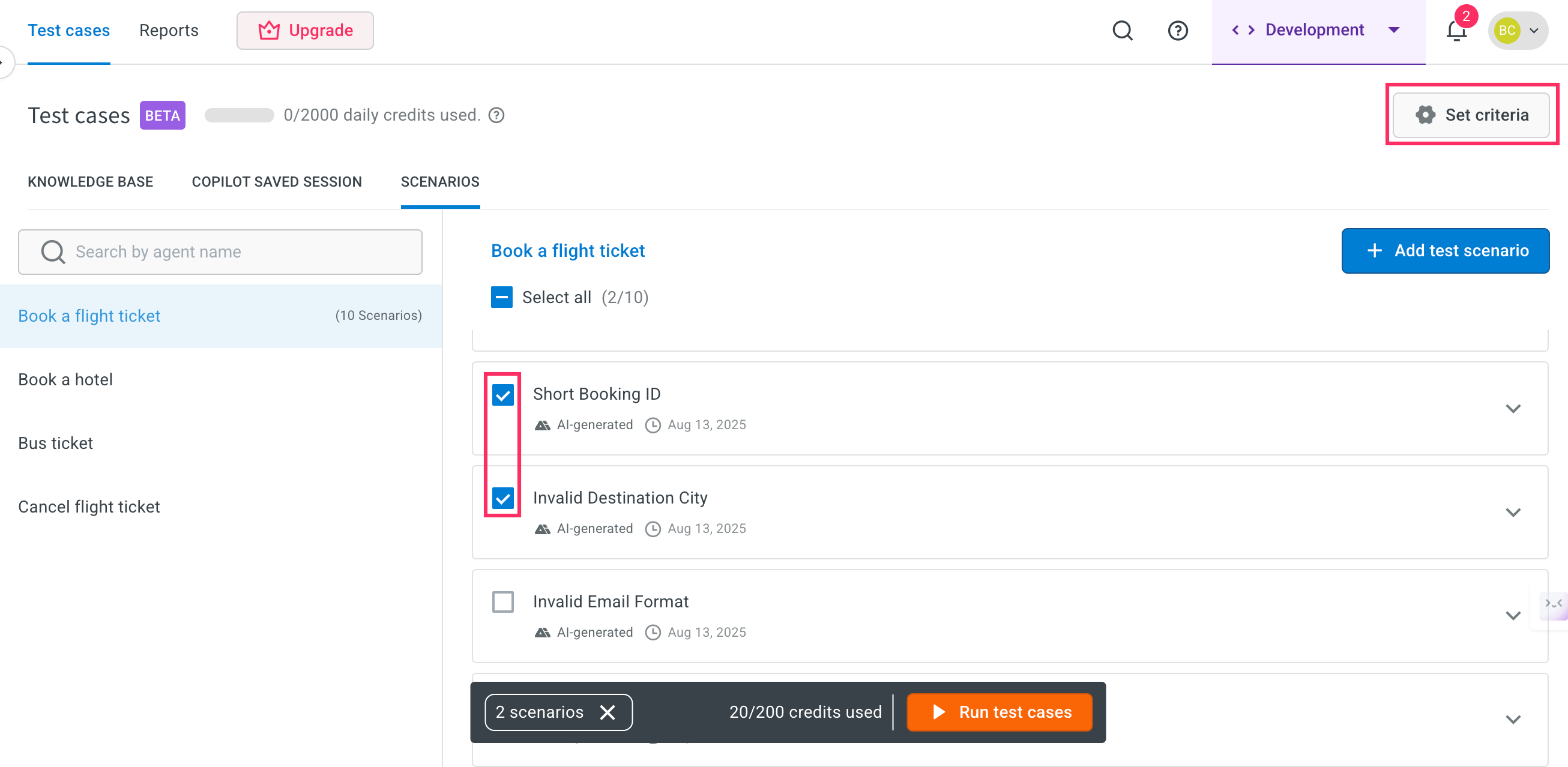
In the Scenarios tab, select the testcases and click on Set criteria for the test case you want to configure.
-
Set the Evaluation rules and click Save.
- Accuracy: Set the empathy level on the slider. This determines how the AI agent's responses match the expected behavior.
Value: 75 – This is the suggested setting for optimal empathy. - Empathy: Set the empathy level on the slider. This ensures the AI responds in a friendly, human-like tone.
Value: 75 – This is the suggested setting for optimal empathy. - Rules: Define rules that the AI agent should follow during test case evaluation.
Example:- Your questions must be phrased differently and varied each time to make it human-like.
- If the user expresses anger or frustration immediately skip to cancellation.
- Accuracy: Set the empathy level on the slider. This determines how the AI agent's responses match the expected behavior.
-
Set Simulation rules: Add the rules to guide how the AI simulates user interactions during testing.
-
If the user provides incomplete information, simulate a natural follow-up question instead of re-asking the original question.
-
Always rephrase questions in a human-like manner to avoid repetition and mimic natural conversation patterns.
-
Run a test case for Scenarios
To run a test case for scenario, follow these steps:
-
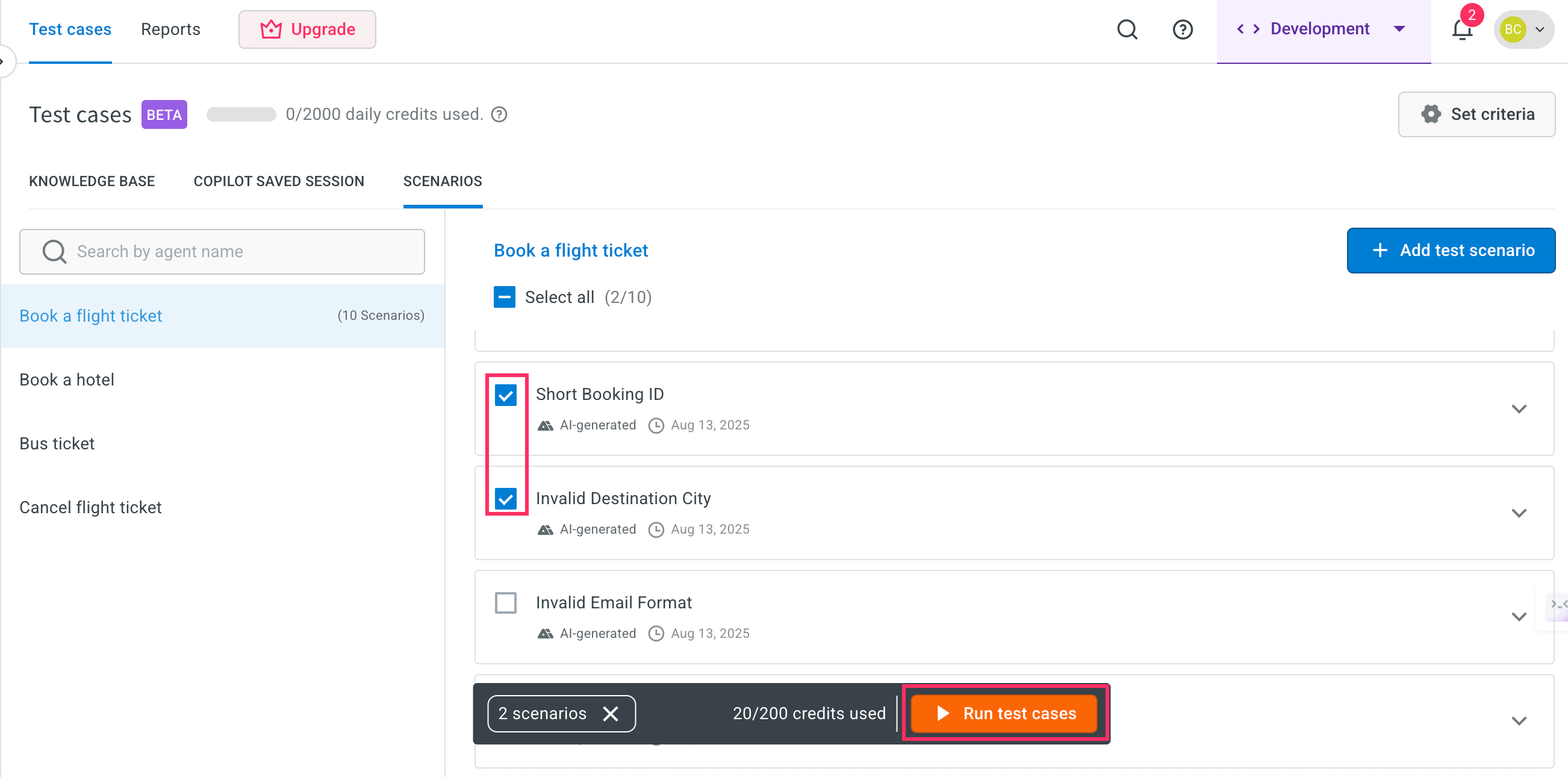
Go to the Scenarios tab. Use the checkboxes to select one or more test cases that you want to run and click *Run test cases.
-
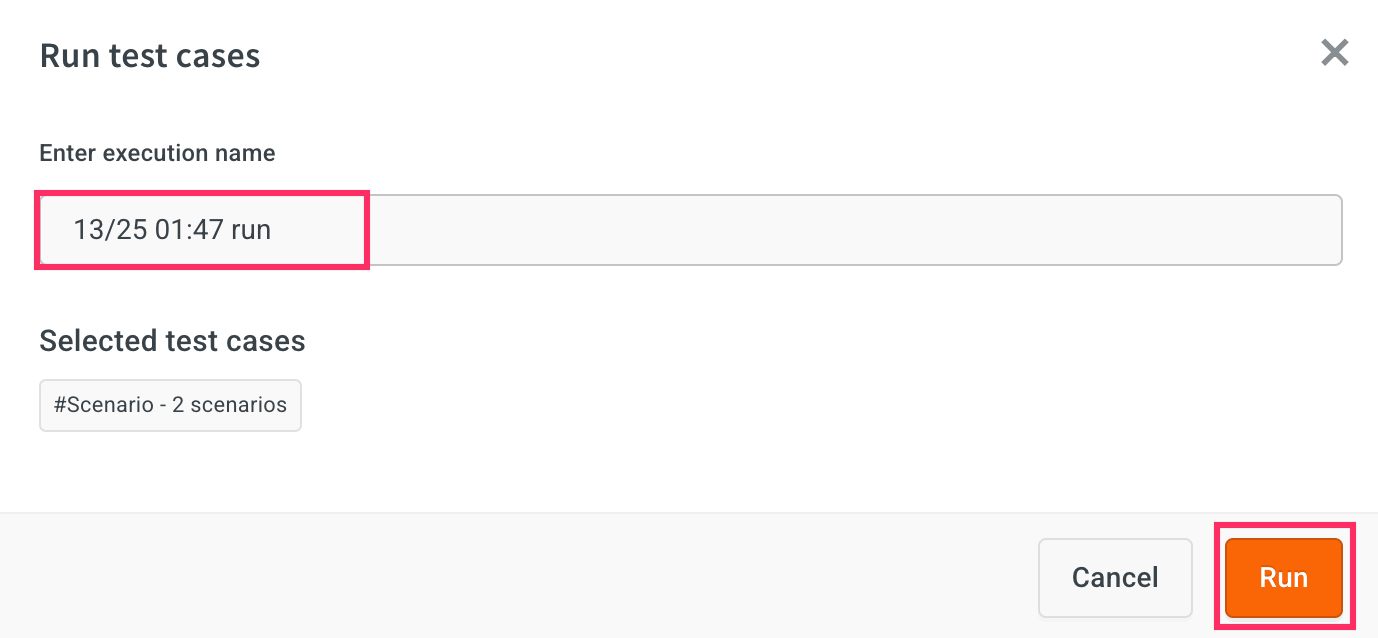
Enter an execution name for the test run. By default, the name will be auto-filled based on the current date and time.
-
Click Run to start the test execution.
-
Click Check reports to view the results of the test case execution.
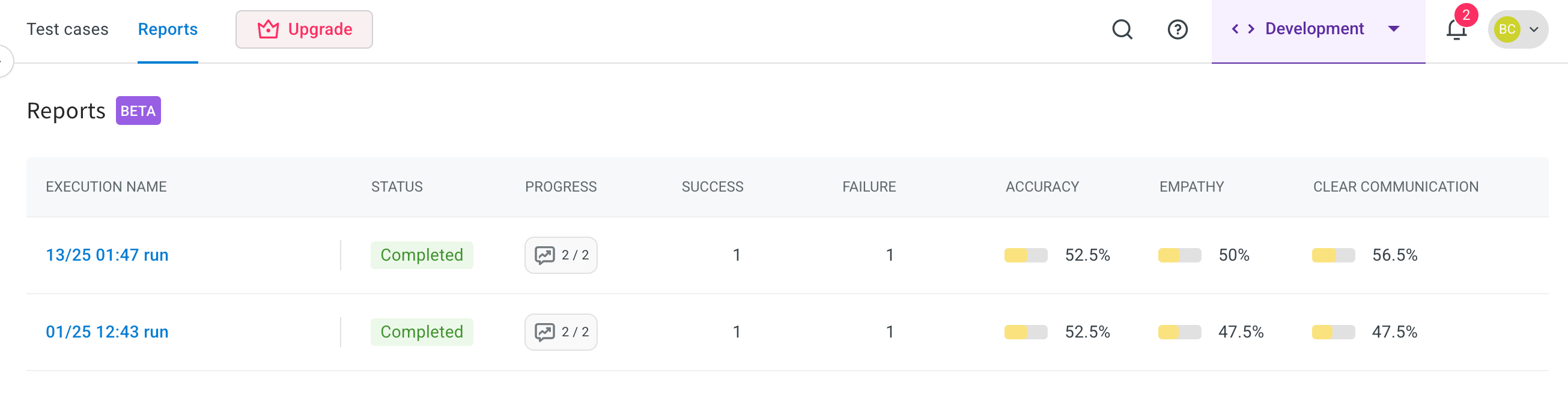
Test Report Overview
In the Report section, you will see a summary of the test execution, which includes:
- Status (Passed/Failed): Indicates whether the overall test scenario was successfully executed or not.
- Success: The number or percentage of test cases that met the expected outcome.
- Failure: The number or percentage of test cases that did not meet the expected outcome.
- Accuracy: Measures how closely the AI agent’s responses matched the expected responses.
- Empathy Score: Evaluates the AI agent’s ability to respond in a human-like, empathetic manner.
- Clear Communication: Assesses whether the AI agent’s responses were easy to understand, concise, and free of ambiguity.
View Scenarios report
After running a scenario test, you can access detailed reports to evaluate how the AI agent performed against the expected behavior.
To view report, follow these steps:
-
Click the Execution name link.
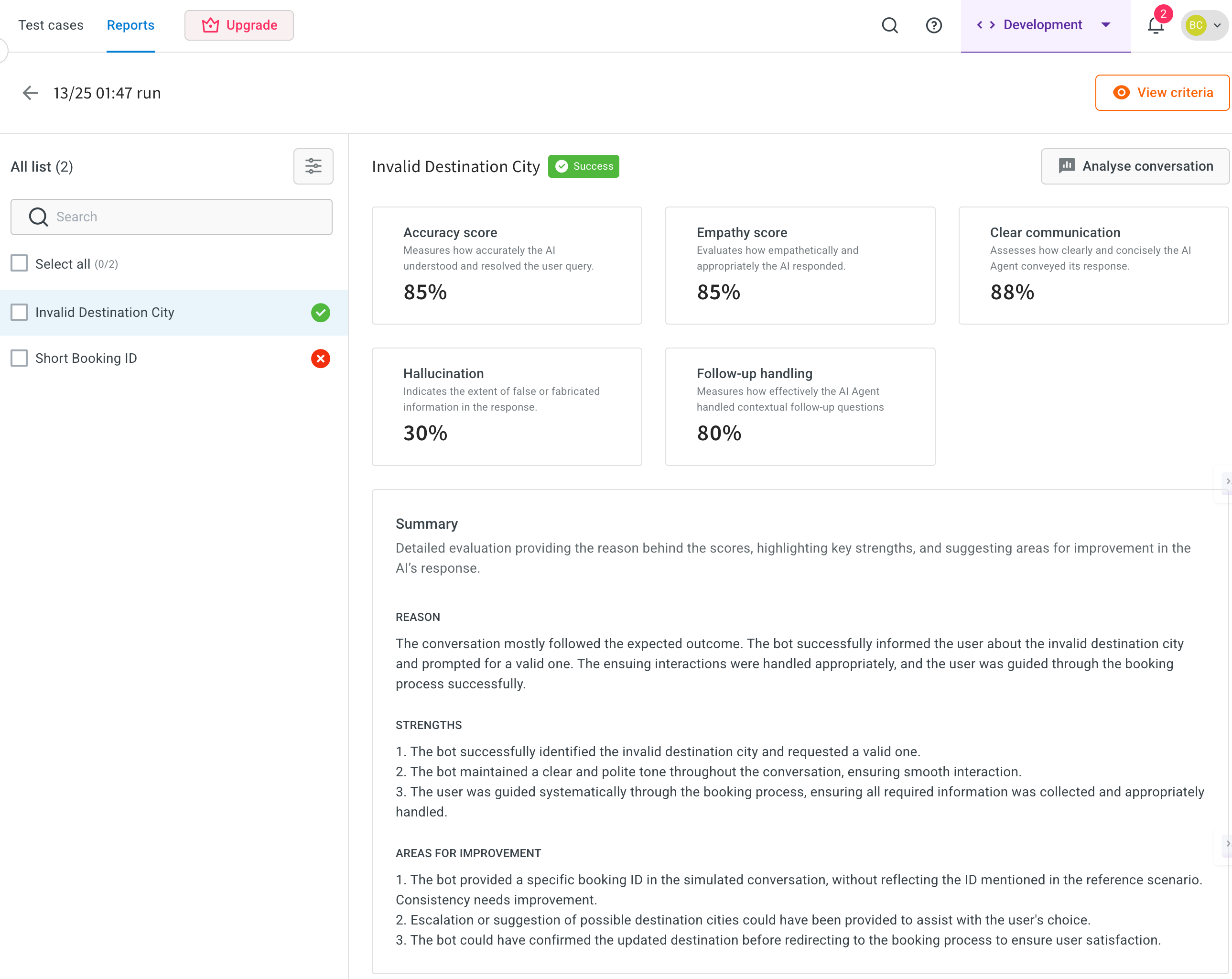
-
This opens the complete report, which provides a comprehensive overview of the AI agent’s performance, including:
- Accuracy Score – How closely the AI agent’s responses matched the expected answers.
- Empathy Score – How effectively the AI agent demonstrated understanding and human-like empathy.
- Clear Communication – Whether responses were easy to understand, concise, and free of ambiguity.
- Hallucination – Instances where the AI agent generated incorrect or fabricated information.
- Follow-up Handling – How well the AI agent managed related or subsequent user queries.
-
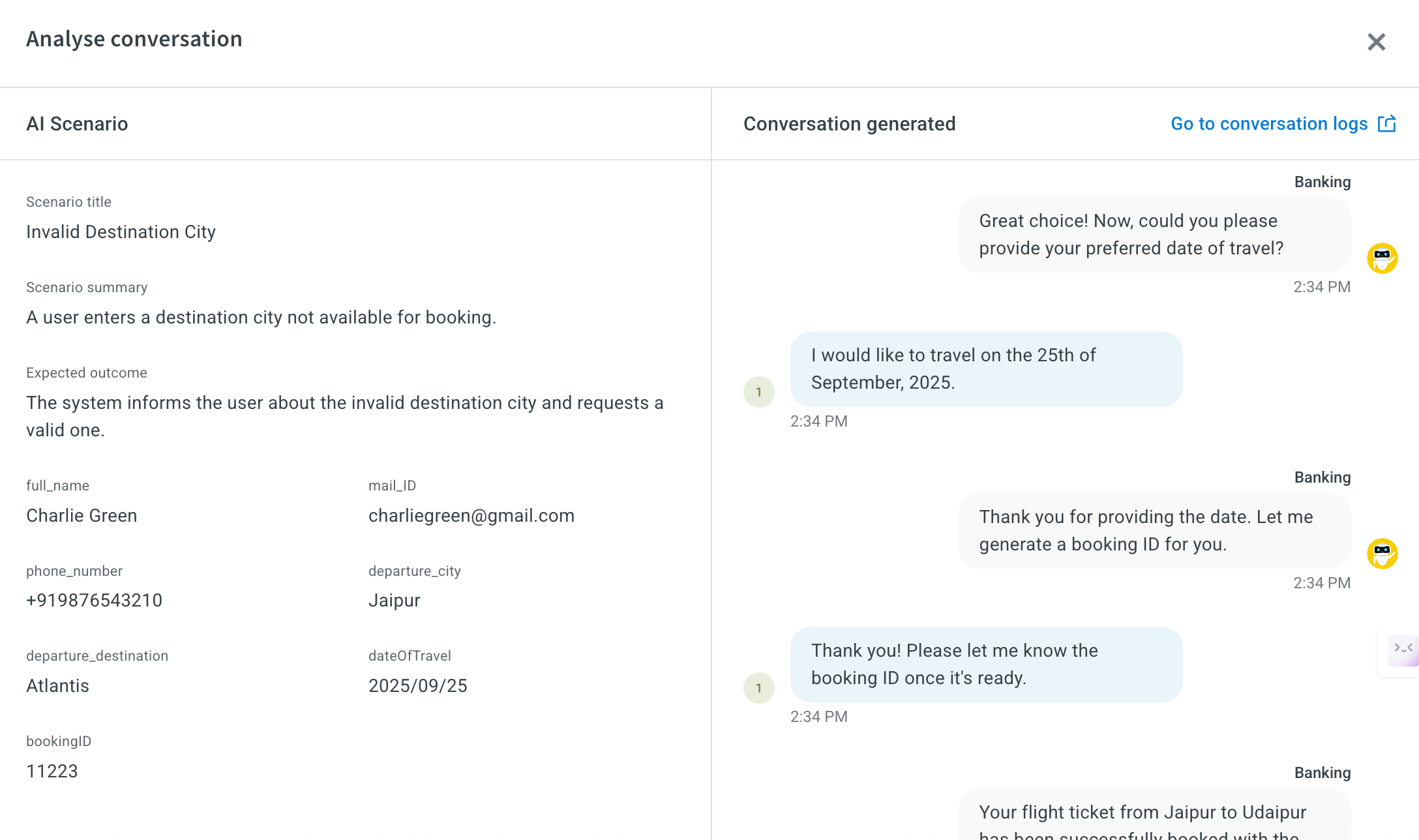
Click on Analyse conversation to review detailed interaction-level analysis.
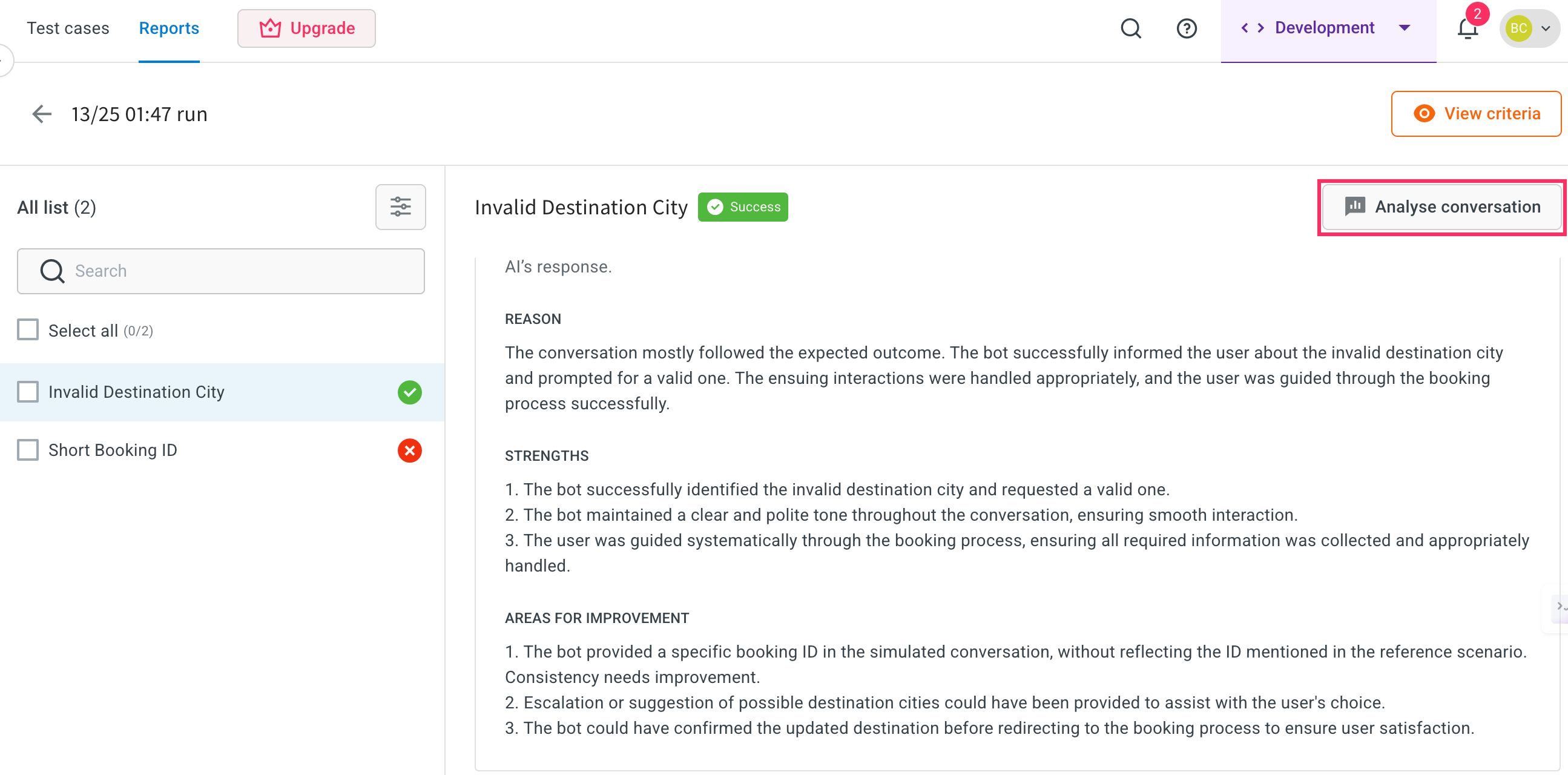
-
In conversation analysis, the following key fields are available:
- Scenario title: The name of the specific test scenario that was executed. This helps you identify which scenario's conversation you are reviewing.
- Scenario summary: A short description of what the scenario is designed to test, giving quick context about the conversation's purpose.
- Expected outcome: The ideal or correct response the AI agent should provide during the test, based on the predefined scenario setup.