Using voice input nodes(prompt) to build a voice agent
The voice input node offers added features that enhance the performance of voice agents. Building voice agents using the "Voice input" node improves conversational experiences with a more natural and human-like interaction style.
- Streamlined SSML handling: Removes the necessity for manual SSML (Speech Synthesis Markup Language) coding.
- Simplified validation process: Integrates validation directly into the flow, eliminating the need for separate configuration.
- Intent and Entity recognition: Facilitates the identification of user intents and entities, enabling the voice agent to understand and respond appropriately to diverse user queries and requests.
- Tracking of unidentified utterances: Provides the ability to monitor and manage unidentified user utterances efficiently.
- Collect PCI-Compliant Data Securely: You can now mark input fields as PCI-compliant to securely collect sensitive cardholder information. When a field is designated as PCI, the platform automatically applies encryption, disables logging, and stores the data using secure protocols.
The following PCI data types are supported:
- Card number
- CVV (card security code)
- Card PIN
- Expiry date
Build a flow with voice input node
Use-case
Consider building a Banking voice agent that asks users questions to identify them and resolve their queries. In this example, the voice agent guides the user through providing their name and phone number to inquire about an eligible home loan, receiving detailed responses.

Let's break down the conversation:
Bot (asks): What is your name?
User (replies): Karan
Bot (stores): Karan as Name
Bot (asks): How may I help?
User (replies): Loan eligibility
Bot (understands): User request = Loan eligibility
Bot (logic): Required phone number to calculate Loan eligibility
Bot (asks): What is your phone number?
User (replies): 9890******
Bot (validates if the number is correct): Uses logic to calculate Loan eligibility
Bot (response): You can avail X amount on X% interest.
--- End of the call ---
For guidelines to build a good conversation, click here.
Steps to configure voice input node
Prerequisite
The Voice Input node will only work for voice agents, meaning you must have enabled Voice agent when creating your voice agent.

Steps to configure
-
Go to Automation > Prompts > Voice input.

-
In Input type, select the type of information you want to capture from the user through voice.
To securely capture PCI-related details, choose one of the supported types. The platform automatically encrypts PCI data and stores it securely with restricted access.- PCI – Card number
- PCI – Card security code
- PCI – Card PIN or
- PCI – Card expiry to capture PCI-related details securely.
noteResponses will be stored in the respective PCI-protected variables.
-
In Bot speaks, enter the message that the voice agent will say to request the user's phone number.
-
In Repeat message, input the message that the voice agent will repeat if the user's response is unclear or requires verification.
-
In Validator, validate the user input against the chosen criteria.
-
In Capturing the user input, configure how the voice agent should gather user inputs.
-
In Additional settings, adjust configurations to enhance conversation authenticity and emulate human-like interactions.
For PCI related inputs, you can Additional Settings to define how PCI data is passed to your API.- Encoding type: Choose how the PCI input is encoded —
Text,Hexadecimal, orBase64. - Card number format: Choose the format in which users are expected to enter the card number. This helps validate and correctly capture card data.
XXXXXXX XXXXXXXXXX-XXXX-XXXX-XXXXXXXX XXXX XXXX XXXX
- Encoding type: Choose how the PCI input is encoded —

Values updated in this node will override the global values.
Example: Configure node for phone number
Following are the steps to collect a user's phone number using the voice input node:
-
In the Input type section, choose the Input type as Phone and enter the messages for Bot speaks and Repeat message fields.

-
In the Validator section, choose Phone in the How do you want to validate user input drop-down and enter the Failure message and No Response message. Mention the Boost Phrases too.

-
In the Capturing user input section, choose Voice and Keypad in the Capture input as drop-down and fill in the rest of the fields.

-
Store the response in a variable.

Input type
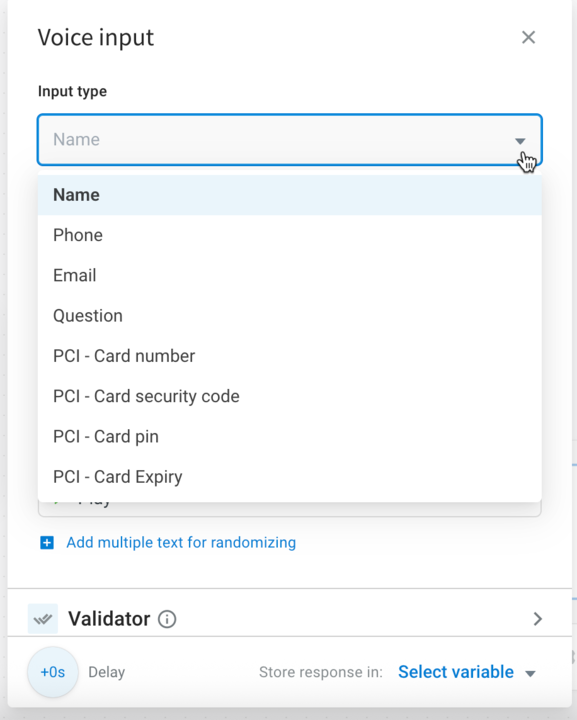
| Field | Description |
|---|---|
| Input type | Choose the type of user response. 1.Name 2.Email 3. Phone 4. Question 5. PCI – Card number 6. PCI – Card security code 7. PCI – Card PIN 8. PCI – Card expiry |
| Bot Speaks | The voice agent's reply that will be vocalized to the end-user during a call. |
| Repeat message | The voice agent's reply that will be vocalized upon the user's request for the voice agent to reiterate the question or prompt. |
You can add multiple messages to all of the above mentioned options by adding random messages . You can also play the message (SSML) to hear the voice agent response.

PCI data masking in voice calls
You can also collect PCI-sensitive information, such as card number, CVV, PIN, or expiry date. When you select a PCI input type, the platform automatically encrypts the data, applies strict logging restrictions, and stores it securely. This data is never retained in logs or databases and can only be accessed securely through the API node.
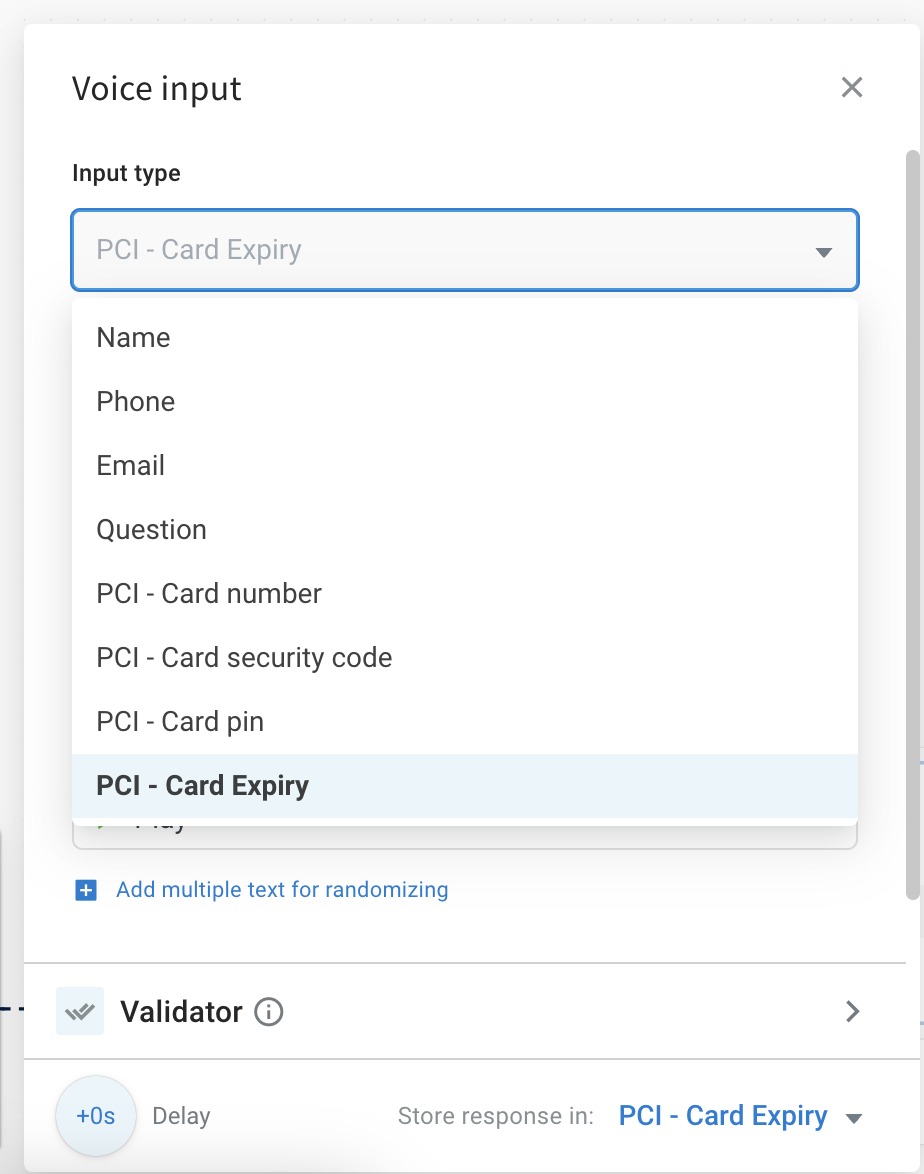
Use Additional Settings to define how PCI data is passed to your API.
- Encoding type: Choose how the PCI input is encoded —
Text,Hexadecimal, orBase64. - Card number format: Choose the format in which users are expected to enter the card number. This helps validate and correctly capture card data.
XXXXXXX XXXXXXXXXX-XXXX-XXXX-XXXXXXXX XXXX XXXX XXXX
Validator
How do you want to validate user input
Choose the criteria against which the user input should be validated.
1. Name
2. Phone
3. Email
4. Intent
5. Entity
6. Regex
7. Intent and entity
You can choose several intents and entity or their combination in the validator. If the user's intention matches any of them, it will be validated, and the flow will move to the next node.

Failure Message
Failure message is vocalized when the validation fails.
- +Add message: Click this button to add up to three successive fallback responses when the voice agent encounters invalid response from the user.
No response message
No response message is vocalized when there is no user response in the configured max response time.
- +Add message: Click this button to add up to three successive fallback responses when the voice agent gets no-response from the user.
You can add upto 3 Failure messages and No response messages each.
Boost phrases
Some user responses can be confusing for the voice agent to understand. Region specific words, new genz lingos, internet terminologies, trending phrases, abbreviations are trained specially so that the voice agent understands the exact intention. For example, COVID is a new term that has been used frequently, the phrase COVID must be boosted, otherwise it gets translated to kovind/ go we/ co-wid etc. Ex - you should add the phrases that you expect from the user response like, < I want to take covid vaccine >

Capturing user input
Capture input as:
You can capture the user response as:
- Voice: Capture only voice input.
- Keypad: Capture only input from the keyboard.
- Voice and Keypad: Capture input from both voice and keyboard.
Voice
| Fields | Description |
|---|---|
| STT engine | Select an engine from the dropdown- Google/Microsoft. |
| STT mode | Select mode from the dropdown. Microsoft provides "Static", "Streaming" or "Streaming Advanced", "Streaming 2.0". Google provides "Static". |
| STT language | Speech-To-Text i.e. transcription language (or user language)(ISO code) can be selected from the dropdown. Click Microsoft or Google for more information on the languages) |
| STT engine endpoint | Optional endpoint of the STT custom model. |
| Recording max duration | This value is the Max duration for which the voice agent will wait after asking a question (in any step) even while the user is speaking. For example, after asking “Which city are you from?” and the recording duration value is “5" - the voice agent records only 5 seconds of user response. This option is necessary to avoid consuming unwanted information and to stay with the conversational flow. If the user mistakenly replies with long paragraphs when a question is asked or if the user's response is getting shadowed with constant background noises, the voice agent must not process those long inputs. Hence, with this configuration, the voice agent only takes the necessary response and can quickly process the user response. |
| Recording silence duration | This value is the Max duration for which the voice agent will wait after asking a question (in any step) for the user to respond. For example, if recording silence duration is 5 seconds, voice agent waits for 5 seconds for the response if the user is silent. If the user does not respond anything within 6 seconds, voice agent Message will be played. |
| Initial silence duration | To provide more customization on the silence duration parameter, “streaming” and “streaming-advanced” STT modes (of Microsoft STT engine) allow to specifically configure the maximum acceptable silence duration before the user starts speaking. For example, the acceptable initial silence duration for the application number question could be higher (~3/4 seconds) but in the case of a quick conversational binary question, it could be configured to 1 second. |
| Final silence duration | Similar to the initial silence duration, the final silence duration is indicative of the maximum duration of pause that the voice agent will wait for once the user has started speaking. For example, for binary/one-word questions like yes/no we could set the final silence duration to ~0.5/1.0 seconds and for address-like fields where taking a pause is intrinsic in conversation, we can set the final silence duration to ~1.5/2.5 seconds. |

Keypad
| Field | Description |
|---|---|
| DTMF digital length | Enter the length of characters to be captured. Ex: For an indian phone number, it is 10. |
| DTMF finish character | Character which defines when the voice agent must stop capturing. Supported finish characters - "*" and "#" |

Voice and keypad
All the above mentioned options for Voice and Keypad will be listed together.

Additional settings
| Fields | Description |
|---|---|
| Enable wait message | Enable this toggle to vocalize an acknowledgement message to the user awaiting a message from the voice agent. |
| Wait message | Acknowledgement message displayed to the user. |
| Recording action | With the recording management options, you can select to pause/resume/stop recording depending upon different use-cases and conversations. By default, the recording is ON. Once you STOP the recording (for recording sensitive dialogues), it can’t be resumed back. |
| TTS engine | Select the engines from the dropdown- Microsoft Azure, Google Wavenet, Amazon Polly. |
| Text type | Select Text/SSML from the dropdown. |
| TTS language | Bot Language(ISO code) can be selected from the dropdown. |
| Pitch | Pitch value can be any decimal value depending on the base of voice required, 0 is ideal. You can add this for Microsoft if text_type = "text" and for Google for text_type = "text" and "SSML". |
| Voice ID | Type the characters of voice ID. You can add this for Microsoft if text_type = "text" and for Google if text_type = "text" and "SSML". |
| TTS Speed | This value defines how fast the voice agent must converse. This value can be 0.9 - 1.5 for the voice agent to soundly humanly. You can add this for Microsoft if text_type = "text" and for Google if text_type = "text" and "SSML". |

Custom response
Custom responses for each identified input
When the system is expecting an input from a user, it handles scenarios where the input doesn't align with expectations. In such cases, customized responses can be used to guide or assist the user. Each input is treated as a condition within an if-else structure. Validators are utilized to define these conditions. For every validation or validator, the voice input node interprets it as a distinct if-else condition. If the user's input matches one of the expected values defined by the validators, the corresponding action or response is triggered. If none of the expected values match the user's input, it's categorized as an unidentified utterance.

Fallback
Fallback nodes can be linked directly to the voice input node. To specify the action in case of encountered issues or call failures, connect the Fallback for failure point to the subsequent node. To proceed with the next action if the user hasn't responded to the input, connect the Failure for no response point to the next node.
Unidentified input storage
When the validation fails, the utterance is saved in the default table along with the following data:
- SID
- Phone Number
- Drop Step [same as the voice input node name]
- Utterance
- Recording URL
- Chat URL
- Language
- Translated Message
- Date & Time (of the call initiation)
- Issue
[UIU / Intent Missing - {{Intent name}}]