Troubleshooting Gen AI bots
The key to troubleshooting bots is identifying the issue. Once identified, you can either retrain the bot with new input or adjust its existing text and parameters for improvement.
Navigate to platform logs
- Open Automation > Build and Preview the bot.
- Click the debugger icon to open the console logs.
- Click Refresh to view real-time logs.
- Review all logs. Click the logs icon to read the log files.

Troubleshooting OrchLLM issues
-
Verify inputs to the OrchLLM: Access this log from [OpenAI] Request details.
- Check if the correct user history is passed to the model under messages.
- Verify that model parameters are correct, such as setting a lower temperature for more contained responses.
-
Verify the response from the model: Access this log from [Yellow LLM Agent] Model output.
- Tools: Identify the model's prediction.
- Reasoning: Evaluate why the model chose a particular tool.
- Response: Check the final response generated by the model for small talk and general queries.
Troubleshooting KB issues
Common Knowledgebase(KB) issues include:
- A query like “xyz” has information in a file/webpage, but it’s not getting answered.
- A query like “xyz” was answered previously but is not being answered now, indicating an intermittent error.
- After publishing, the KB is not working as expected.
- The sandbox KB response differs from the staging KB response.
For further evaluation, consider the following:
Identify if it’s a KB issue
- Check Conversation Logs: Look for the KB Response node.

- Verify Query Reach: Visit Data Explorer > Knowledge Base report 30-45 seconds after the query. If the query has reached the KB, you should see a row with the query, search results, and response.
Components to check
You must check the input, the search results generated by the KB, and the final response.
Input
- Query
- Conversation history (rephrase query)
- Site key (optional, for Bing search websites)
- Tags (optional, for file tags)
- Search confidence (default is 0.5)
- Model type (optional, with InHouse LLM) source
- Knowledge version

Search
- Does the answer exist in the KB index?
- Is the relevant paragraph among the top 20 results for that query (check the KB report)?
- Is the paragraph LLM-friendly (e.g., does it contain table data)?
- What is the position of the knowledge?
- Has the knowledge version changed?
- Are there conflicting or similar results?

Response
- The final output from the response model is shown as the answer.
- Depending on use-cases, you can change the background model and prompt it to follow custom rules. Note: This has implications for cost and hallucination.
- Rules cannot be defined here; it’s a prompt that requires iterations.
Refer to this document for details.
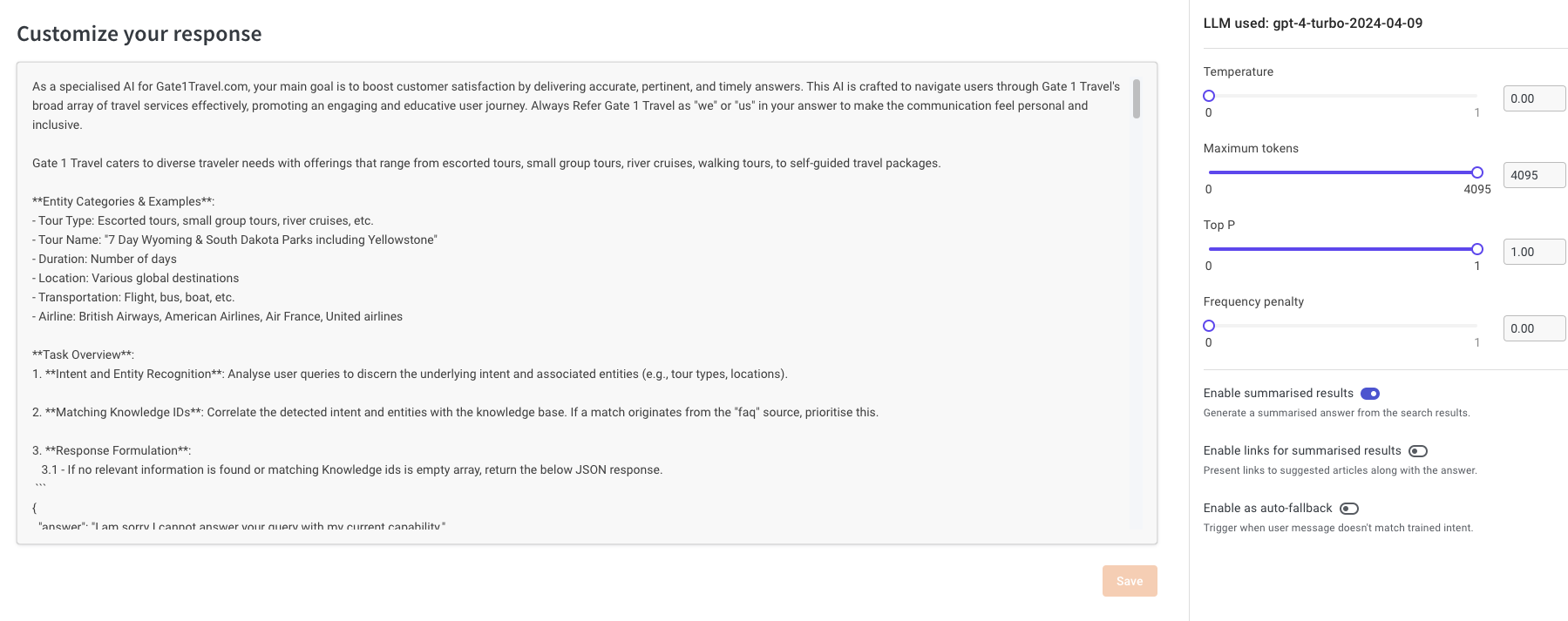
info
Troubleshooting Reference Docs